Many encoding practices are common to all types of LEMDO XML files. Subsequent chapters
deal with particular types of files (modernized texts, annotations, etc.), but you
will want to come back to this chapter on a regular basis to remind yourself of general
encoding principles and practices.
Learning Outcomes
This chapter is designed to support you through all of your encoding work. By the
time you have worked through this chapter, you will:
Understand what you are and are not able to do while encoding with LEMDO.
Know how to name a file.
Be able to create unique xml:ids.
Know how to track your work using the
<change>
element and
@status attribute.
Be able to encode titles.
Be familiar with encoding practices for split elements.
Know the tools that LEMDO has created for editors and encoders.
There are some common pitfalls when working on the LEMDO projects that can be avoided
by following standard practices when you work. In addition to following the recommended workflow for working in the command line, adding content to files in according to these standard practices ensures that you
limit validation and diagnostic errors in your work. This documentation will guide
you through practices that will ensure your work does not cause errors.
Avoid Copying From Word Files
Word files from any era and especially from the early days of word processing contain
hidden characters that will break the LEMDO build. Do not copy and paste directly
from a Word file (a file with a .doc or a .docx extension) into an XML file. If you must copy content, put it in a text editor first
and save it as a text file. Before you copy the text to paste into Oxygen, check the
file extension of the file from which are copying. It must be .txt.
All PCs have a text editor already installed. If you would like to use a different
text editor than the one already installed on your computer, there are many options
available. Commons ones are Notepad (Windows OS), Text Editor (Linux Ubuntu OS), Atom,
BBEdit, and SimpleText (Mac OS).
Always Open Oxygen Project File First
It is imperative that you begin every work session by opening the lemdo-all.xpr project file. This file contains important scripts that control the behaviour of
Oxygen and give you access to tools that we have built especially for LEMDO users.
The XPR file also ensures that you are validating your XML files against the schema
and Schematron that determine how you are supposed to encode your play; the schema
and Schematron catch your mistakes and prompt you to correct them. See LEMDO Oxygen Project.
Note that if LEMDO is the only project that you work on in Oxygen, you will not need
to follow all of the steps to open the LEMDO XPR file at the start of each work session.
Oxygen automatically opens the project that you worked on most recently. It is, however,
good practice to check that you are in the LEMDO project by opening the project view
pane in Oxygen and ensuring that it shows lemdo-all.xpr as the project file.
Validate Your Files Before Committing
Any file that you commit to the repository must be valid. It must follow the rules
that are embodied in the schema and Schematron. An invalid file can break the build process. If you open the lemdo-all.xpr file first before
you open any other file, then you can be sure that you are validating against the
LEMDO schema and Schematron. See Validate Files.
This document explains LEMDO’s naming conventions. Note that the principles set out
in this document apply only to TEI-XML documents and related source materials; other
naming conventions are covered in LEMDO Programming Principles
Introduction
All LEMDO files must have descriptive file names. LEMDO has established a set of naming
conventions to ensure that file names are both unique and descriptive. This documentation
will guide you through the conventions for our different naming groups:
Editions
Anthologies
Images
Facsimiles
Performances
Documentation
Databases
Principles
While we have specific naming conventions for different groups, there are some principles
that are true across the LEMDO project:
Give all files that you create for the project—even word-processor files with notes
in them—descriptive file names.
All file names must be unique. Check for uniqueness against the A–Z list of xml:ids
used in the LEMDO project by clicking the Resources button in the top navigation bar of the LEMDO-dev website and then selecting All xml:ids (.txt version). In the A–Z list, search for the ID that you wish to use to ensure it has not already
been used.
Never use spaces in file names.
Never use punctuation other than underscores in file names.
Always use lowercase for file extensions (i.e., .jpg, .png, .xml).
Note that while SVN can handle punctuation characters in file and folder names, files
with punctuation and spaces in their names can still cause problems when they are
turned into HTML files. To prevent such problems, always follow the above principles.
For example, rather than naming a file Fred’s notes on documentation.odt, use Fred_notes_on_documentation.odt.
Practice: Name Edition Files
Our practice for naming edition files follows scholarly conventions for play naming.
IDs for Shakespeare plays have long been standardized; they are even listed in the
Chicago Manual of Style and the MLA Handbook. The Digital Renaissance Editions anthology has extended the implied principles for naming Shakespeare plays to all
other plays. We use those IDs for editions.
When giving edition files a name, consult DRE Play IDs to find the ID for the play that you are adding. You can search for the play’s title
using Ctrl+F (Cmd+F on Mac). If you cannot find the title you are looking for, contact
the LEMDO team, who will in turn consult with the DRE Co-Coordinating Editor Brett D. Greatley-Hirsch,
who has established IDs for his own LEMDO-adjacent project, Bibliography of Editions of Early English Drama (BEEED). LEMDO adopts BEEED’s IDs for all non-Shakespearean plays.
Once you have the ID for your play, you will format the file name as emd followed by the play ID followed by an underscore and a descriptive identifier (e.g.,
genIntro or annotation). For example, the semi-diplomatic transcription for the first quarto of An Humorous Day’s Mirth (ID “AHDM”) is emdAHDM_Q1.xml.1
Standard descriptive identifiers:
Page Type
Identifier
Edition page
edition
Semi-diplomatic transcription of a folio text
F (often followed by folio number, e.g., F1)
Semi-diplomatic transcription of a quarto text
Q (often followed by quarto number, e.g., Q1)
Collation
collation
Modernized text
M
Annotations
annotations (some legacy files have “Annotations” in their titles)
General introduction
genIntro (some legacy files have “GenIntro” in their titles)
Textual introduction
textIntro (some legacy files have “TextIntro” in their titles)
Bibliography
bibliography (some legacy files have “Bibliography” in their titles)
Critical introduction
critIntro (some legacy files have “CritIntro” in their titles)
Practice: Name Anthology Files
The file names for all anthology about pages must begin with the abbreviation for
the anthology in lowercase letters (i.e., dre, emee, emdp, moms, qme, etc.). Following
the anthology abbreviation, add an underscore and a descriptive identifier. For example,
the file on the history of the DRE anthology is named dre_history.xml.
Images
LEMDO has slightly different naming protocols for image files depending on whether
the images are for an edition, an anthology, or LEMDO documentation:
Images for editions: Format as your edition ID followed by an underscore and a descriptive
identifier. E.g., HW_almanac.jpg
Images for anthologies: Format as your anthology ID followed by an underscore and
a descriptive identifier. E.g., moms_hughAlley_mayor.jpg
Images for documentation: Format as the name of the documentation file that the image
will be included in followed by an underscore and a descriptive identifier. E.g.,
learn_editorTools_projectView.png
LEMDO’s convention for facsimile file names is to include the ID of the text to which
the facsimiles are connected. When you name a facsimile file, format the file name
as: facs followed by an underscore, then your edition ID, another underscore, the siglum,
another underscore, the library ID, another underscore and the copy number (if there
is one). The pattern to follow is facs_work_siglum_library_copy.xml.
For more information on naming and saving facsimile files, and for a table containing
the IDs for holding libraries, see Name and Store Facsimiles.
Practice: Name Performance Video Files
Performance video metadata files should be named as follows: emd, the edition ID, an underscore, and the word video (if the file describes a video of the entire performance). If the metadata file captures
information about a video recording of a scene or an act, add an underscore followed
by scene or act and the number of the scene or act. Normally, it makes more sense to provide recordings
of scenes rather than acts.
Note that when we include act or scene numbers, we always keep the number of digits
the same. If there are more than ten scenes in your play, all numbers in the performance
file names must have two digits (e.g., _scene01, _scene02 … _scene09, _scene10). Because there are typically a maximum of five acts, we only need to have single
digit numbers (e.g., _act1, _act2 … _act4, _act5).
The following table gives the specific pattern to follow for each scenario of performance
videos:
Scenario
Pattern
The file contains the metadata for the video of the entire performance.
emdABBR_video.xml
The file contains the metadata for the video of a single scene and the play contains
ten or more scenes.
emdABBR_video_scene01.xml
The file contains the metadata for the video of a single scene and the play contains
nine or fewer scenes.
emdABBR_video_scene1.xml
The file contains the metadata for the video of a single act.
emdABBR_video_act1.xml
Examples: emdFV_video, emdFV_video_scene09.
Practice: Name Documentation Files
All documentation files should start with learn, followed by an underscore, followed by a descriptive identifier. For example, the
file name for this documentation file is learn_namingConventions.xml.
IDs for sitewide databases must be structured as follows: XXXX#, where X is an uppercase
letter and # is a number consisting of one or more digits.
The letters and numbers used for infrastructure IDs are not arbitrary: use the first
four meaningful letters of the title of the file. If the file you are naming uses
a particular 4-letter combination for the first time in our database, the number will
be 1. Otherwise, find the next available number in the A–Z Index for this particular
4-letter combination. For example, when you create a personography file, the first
four letters are “PERS.” Given that our sitewide personography file was the first
instance of this letter combination, the number was 1: PERS1.xml. Do not make a new personography file unless you been instructed to do so by the
LEMDO team.
Always check your ID against the A–Z Index before finalizing it and committing the
file. You can access the A–Z Index through the LEMDO-dev site by clicking on Resources in the top navigation bar and selecting All xml:ids (.txt version).
LEMDO uses
@xml:id attributes across the project to give unique identifiers to various entities: people,
productions, sources, projects, organizations, characters, divisions in documents,
paragraphs in documents, and anchors in documents. We have thousands of
@xml:id attributes in the LEMDO project, and the value (ID) of each one of them must be unique across the entire project. Duplicate IDs will break the build.
Principles
No matter the type of file, some principles are true for all xml:ids that you create:
All xml:ids must be unique through the entire LEMDO project.
The xml:id for a file must match the filename (e.g., the file named emdH5_FM.xml has an
@xml:id value of emdH5_FM. Note that you do not need to include the file extension in the xml:id.)
Within a file, all xml:ids must begin with the xml:id of the file followed by an underscore
(e.g., all xml:ids for paragraphs in the file with xml:id emdHW_GenIntro must begin with emdHW_GenIntro_).
Practice: Give Entities in Your Edition Unique IDs
For edition files and identifiers within edition files (paragraphs, acts, scenes,
speeches, etc.), we meet the need for uniqueness by insisting that every
@xml:id value begin with emd followed the abbreviation of the play. For example, every xml:id created for the
edition of Famous Victories begins with emdFV. This ensures that each file is unique to the edition.
Practice: Give Entities in Your Anthology Unique IDs
For anthology pages, we meet the need for uniqueness by insisting that every
@xml:id value begins with the abbreviation for the anthology. For example, the About page for QME has the
@xml:id value of qme_about, which is also the name of the file (qme_about.xml). The About page for DRE has the
@xml:id value of dre_about. (Note that when we build your final anthology, we remove the qme_ and dre_ portion of the file names to keep your final, public-facing URLs lightweight.)
Practice: Create Unique IDs for Entities in Sitewide Databases
This section pertains mainly to LEMDO Team members at UVic: when you are creating an
@xml:id value for an entity in one of the sitewide database files (PERS1, PROS1, GLOSS1,
HAND1, BIBL1, PROD1, ORGS1, or TAXO1), you must check the complete list of LEMDO
@xml:id values to ensure that you are creating a new value. These ids are generally four
uppercase letters followed by a number (JENS1, SHAK1, ADAM1, LEMD3, and so on).
You can view all the
@xml:id values in the project (except for the anchor, speech, and paragraph IDs) from the
LEMDO-dev site. Note that you must be looking at the most recent build of the site
to see the most recently added xml:ids. To this end, we recommend that you refresh
the LEMDO-dev site regularly. To view a .txt list of all xml:ids used across the LEMDO
project:
Click on the Resources button on the top navigation bar of the LEMDO-dev website.
Select All xml:ids (.txt version).
Search for the ID that you wish to assign using Ctrl+F (Cmd+F on Mac). If it is already
taken, assign the next available xml:id. For example, if you want to create an ID
beginning with ADAM, search the page for the string ADAM. If your search shows that ADAM1, ADAM2, and ADAM3 have been used, then the next available ID is ADAM4.
Note that this is a lightweight page that loads quickly but does not give any details
about the entity that the xml:id is used for. For this reason, this page is useful
mainly for determining whether or not an ID has been used already.
Practice: Create Unique IDs for Entities in Documentation
All xml:ids in documentation must begin with learn followed by an underscore. The value after that should be descriptive. For more information
on creating an xml:id for a documentation page, see Create and Name Documentation Files.
To ensure that the xml:id is unique, check list of all xml:ids on the LEMDO-dev site.
Practice: Find Duplicate IDs in a File
If you do get a validation error related to duplicate IDs in your file, it can be
a time consuming and difficult task to find the duplicate xml:ids. You can use XPath
on your invalid file to find the duplicate xml:ids. To do so:
Right click on your file in Oxygen’s project pane.
From the drop-down list, select XPath in Files…
In the XPath pane now open on the right side of your Oxygen window, paste the following
XPath to find the first instance of a set of duplicate IDs: //*[@xml:id = following::*/@xml:id]/@xml:id
Click the red play button at the top of the XPath pane to run the XPath in the file.
This will navigate to and highlight the first instance of the duplicate IDs.
Copy the value of the
@xml:id attribute.
Use Ctrl+F (Cmd+F on Mac) to open your find/replace window in Oxygen.
In the Find box, paste the duplicate xml:id that you had copied.
Click the Find All button.
Update the xml:ids so that they all have unique values.
Make sure that you update any links to the updated ID.
Reference Table of xml:id Formats
Entity Type
xml:id Format
Example(s)
File in a LEMDO edition
emdABBR_identifier
emdMucd_copies
Section of a critical paratext, anthology about page, or documentation page (
<div>
)
LEMDO uses the
@status attribute on two elements in the
<teiHeader>
of files: the
<revisionDesc>
element and the
<change>
element. On the
<revisionDesc>
element, we use the
@status attribute to track the current status of a file. On the
<change>
element, we use
@status to record milestones in the file’s progress towards publication. Between the two
elements, the
@status attributes in a document determine:
The schema and schematron requirements that the document must meet to be valid. Some
schema and schematron rules do not apply to files with certain statuses.
Whether we can publish a document. We do not publish documents until they have a
@status value of published.
What date we record as the date of publication. The date (encoded with the
@when attribute) on the
<change>
element with a
@status value of published is the date of publication for that file.
If LEMDO’s processing should add a label indicating that the document is peer reviewed.
Only files that have a
<change>
element with a
@status attribute with a value of peerReviewed get a peer review label.
In addition to the processing value of the
@status attribute, the information recorded with it is useful to the LEMDO team for tracking
our process.
This documentation will guide you through the process of changing the value of the
@status attribute on the
<revisionDesc>
element and adding
@status attributes to
<change>
elements.
Practice: Update the Status on the Revision Description
Every encoded file (with the exception of documentation files) must have a
<revisionDesc>
element in its
<teiHeader>
. This element must contain a
@status attribute that documents the current stage of the file’s encoding process.
Change the value on the
@status attribute when:
You create the file.
You begin encoding the file and the status does not end in _INP. INP stands for “in progress,” so any files that are in the process of being encoded or
remediated should have a status indicating that they are being worked on. This triggers
schema and schematron rules to apply to the file, so you may get validation errors
as soon as you change the status. Ensure that you resolve those errors before committing
the file.
You finish encoding a file and it is ready to be proofed. Change the value of the
@status attribute to draft.
You begin proofreading a file and the status does not end in _proofing. Files that are in the process of being proofread should have a status indicating
that the proofing is in progress.
You finish proofreading a file and there are no edits to be made. Once proofreading
is complete, the value of the
@status attribute should end in _proofed.
LEMDO publishes the file. One of the last tasks before releasing an anthology is to
change the status of all files included in the release to published.
You deprecate the file but keep it in the LEMDO repository for archival purposes.
LEMDO tracks the progress of files with
<change>
elements that are children of the
<revisionDesc>
element in each encoded file. The
<change>
elements record changes in the file, including when those changes are made and who
they were made by. When we change the status of the file, we also add a
@status attribute to a
<change>
element to create a permanent record of when the file changed status. We also add
a
<change>
element with a
@status attribute when a file goes through peer review so that a peer review label is added
to the rendered Web page for that file.
Note that you do not need to add a
@status attribute to every
<change>
element. Only add
@status when the file changes status or goes through peer review.
Table of Predefined Document Status Values
Value of
@status
Description
prgGenerated
The document has been programmatically converted from IML to LEMDO TEI P5 via a series
of transformations. The file is a .xml file.
IML-TEI
There are stray IML tags in these texts that we retain until we have proofed the TEI.
If the file is a semi-diplomatic transcription, the IML may have been checked by an
ISE editor but LEMDO has not yet checked it.
IML-TEI_INP
The converted file is being remediated by a member of the LEMDO team.
IML-TEI_proofing
The converted file has been completely remediated and is currently being proofread.
IML-TEI_proofed
The converted file has been proofread and corrections have been made if needed.
TCP-TEI
The file is a semi-diplomatic transcription that has been programatically converted
from TCP TEI P4 to LEMDO TEI (P5) via a series of transformations. The file is a .xml
file. The transcription is only as correct as the underlying TCP transcription (which
contains gaps, errors, and normalized long s characters). The TCP metadata is retained.
TCP-TEI_INP
A LEMDO team member is correcting the transcription in the converted file against a digital surrogate
of the early modern playbook and is updating the encoding to comply with LEMDO’s customization
of TEI P5.
TCP-TEI_proofing
The converted semi-diplomatic transcription has been completely encoded and styled
and is currently being proofread.
TCP-TEI_proofed
The converted semi-diplomatic transcription has been completely encoded and the transcription
has been corrected by a member of the LEMDO team. The completed semi-diplomatic transcription has been proofed as a rendered HTML
page by the editor and as an XML file by another member of the LEMDO team.
TEI_INP
The file was created as a TEI-XML file and is being encoded in TEI.
TEI_proofing
The file has been completely encoded in TEI and is now being proofed.
TEI_proofed
The text has been proofed.
published
The file has had its metadata updated and is included in an anthology release as a
published file.
converted
The file has been converted from another encoding language.
draft
The file has been completely written and encoded, but is not yet being proofed by
someone.
empty
Files that are empty. Files should not permanently have this status.
deprecated
This document is no longer relevant, but is being preserved for archival purposes.
Any files with this status should be moved to the obsolete directory.
Note that these values follow the typical format: [original file type]-TEI_[current status of file]. Where the file began as a TEI-XML file, there is no original file type necessary.
We use the
<change>
element to track our work because it offers a mechanism for tracking who did what
work on each file and because it allows future encoders and editors to see what has
been done to the file before they continue work on it. It is especially important
for LEMDO team members to add
<change>
elements when we make interventions in files whose editors are actively working on
them. When the editor opens the file, they will need to know what we have changed
in the file. Likewise, editors’ change elements are helpful to the LEMDO team.
Practice: Start Your Work
When you begin encoding a file, add a
<change>
element as a child of the
<revisionDesc>
. On the
<change>
element, put the
@who attribute with a value of pers: followed by your xml:id, the
@when attribute with a value of the date you did the work given in ISO format (yyyy-mm-dd),
and, if you are changing the status of the file, the
@status attribute. These indicate who you are, the date you started remediating, and the
status of the file. Add a statement for what you are doing in the file in the text
node (e.g., began remediating file). For example:
Note that the
@status attribute is added to the
<change>
element only when you create a file or when you change the status of a file.
Practice: Track Significant Writing or Encoding Tasks
Add other
<change>
elements during the encoding process to indicate when you complete significant writing
or encoding tasks. For example, you may want to make note of when you finished numbering
<lb>
elements in semi-diplomatic transcriptions. While it is optional to add
<change>
elements in each work session, it is good encoding practice to do so. You should
always add a
<change>
element when you begin work on a file and when you finish work on it.
For example:
<change who="pers:GALL2" when="2022-06-06">Fixed the wlns following Hinman’s rationale. This file should be ready for JENS1 to
review.</change>
Practice: Complete Your Work
When you have completed your work on a file, add a
<change>
element. Put important and relevant information about your file in the text node
of this
<change>
element, such as what you have completed and what must still be done in it. This
protocol ensures that another encoder will be able to continue work on your file if
there is any further work that must be done on it. For example:
<change who="pers:GALL2" when="2022-12-13">Completed the feedback from JENS1 and finished up the file. There are no facsimile
links because it is only on EEBO. EEBO is listed in the source desc for now. A future
encoder will need to add links when we obtain our own facsimile.</change>
If you are changing the status of the file, add a
@status attribute. For example, if you have completed all encoding work in a file, add a
@status attribute with a value of draft. We put a
@status attribute on
<change>
elements along with the
<revisionDesc>
element to keep a record of when the status of the file has changed.
TEI allows the
<title>
element in both the
<teiHeader>
(the metadata) and the
<text>
element. Including two titles may seem redundant, but it allows you to make a helpful
distinction between the title of your XML file and the title of the text captured
in the XML file (e.g., the play title).
For born-digital texts, the title in the
<titleStmt>
is the title that will show up on the webpage. This title is distinct from the file name, which is generally truncated and must exactly match the xml:id of the file.
For primary texts, LEMDO aims to standardize file naming practice while still allowing
some editorial flexibility in play titles. Shakespeare’s plays have authority names established by convention, long usage, and lists like the one in the MLA Handbook. We should be aware that for DRE plays, we will often be in the situation of establishing
what will became a de facto authority name. (See DRE Play IDs.) As we do that work, we can also pay lively attention to the complexities of titles
in the EM period.
Practice
LEMDO uses the
<title>
element in the following ways:
To give titles to documents encoded as XML files.
To capture the title pages of early modern playbooks in our semi-diplomatic transcriptions.
To capture the titles given on the first page of early modern playbooks in our semi-diplomatic
transcriptions.
To give titles to entire editions by encoding the title in an edition page (think
of edition pages as a hybrid of the title page of a printed book and the table of
contents).
To give titles to modernized text.
To give titles to anthologies in the anthology home page.
You will find more information about titles for the various components of your edition
in the relevant chapter for each component linked to in the table below.
Overview
Title Type
Title Location
Parent Element
Element
Attribute
Values
Example
Born digital
<teiHeader>
<titleStmt>
<title>
@type
main
Textual Introduction
Titles of semi-diplomatic transcriptions
<teiHeader>
<titleStmt>
<title>
@type
main
Northward Ho, Quarto 1
Titles on title pages (semi-diplomatic transcription)
Because of the hierarchical organization of elements, it is sometimes impossible to
capture fragmented parts of a text within a single element. Thus, we need a way to
connect these parts even when they are wrapped in separate elements. The linking
@next and
@prev attributes are one way to point to discontinuous segments. Combined with the
@xml:id attribute, they can be used to connect parts of the text that are separated because
of the need to maintain the hierarchy of TEI elements.
Practice: Encode Split Elements
You will most commonly use the
@next and
@prev attributes to connect quotations that span multiple lines and letters that are interrupted
by dialogue, but they are not limited to these usages.
To encode split elements, first add an
@xml:id attribute on each element that you are going to connect. Give each
@xml:id a unique value using the following practice. Begin the value for each
@xml:id with the xml:id for the file (i.e., emdABBR); followed by an underscore and the name of the element that the
@xml:id attribute is on; and finally an underscore and a number unique in the file (e.g.,
emd2H4_M_q_1). By making each element in a series unique, we can assign them a place in the sequence
in relation to the other unique elements.
After assigning
@xml:id values to each element in the series of fragments you want to connect, add the
@next and
@prev attributes to the elements. We use the
@next attribute to link to the next element in the sequence. The value of
@next will be the xml:id that you gave the following element in the sequence preceded by
a hash character. We use the
@prev attribute to link to the previous element in the sequence. The value of
@prev will be the xml:id that you gave the preceding element in the sequence.
In this example, the first verse line in a quote links to the second using the
@next attribute and the second verse line links to the first using the
@prev attribute:
<sp><!-- … --> <l> <q xml:id="emdH5_FM_q_1" next="#emdH5_FM_q_2">When the man dies, let the inheritance</q> </l> <l> <q xml:id="emdH5_FM_q_2" prev="#emdH5_FM_q_1">Descend unto the daughter.</q> Gracious lord,</l> <!-- … --> </sp>
Note that the first fragment in the sequence that you assign a
@next attribute to will not have a
@prev attribute because there is no previous fragment in the series to point to. Likewise,
the last fragment in the series will have no
@next attribute. All fragments between the first and last must have both the
@next and
@prev attributes.
This is a list of elements which most commonly need the
@next and
@prev attributes, with some scenarios in which they will be required:
<lg>
: In modernized texts, a character may interrupt a song or verse letter with prose.
We want to indicate that the separate lines of the song are part of a larger whole
of the song, so we must link the
<lg>
elements with
@next and
@prev.
<p>
: Similarly, a character in a modernized text may interrupt their reading of a prose
letter, and we want to indicate that the lines of the letter are part of a larger
whole.
<q>
and
<quote>
: In modernized texts, characters’ quotations may span multiple verse lines, although
quotation elements cannot, so we need to link the separate quotation elements together.
Example: Quotations Spanning Multiple Lines
Sometimes a character’s quotation spans more than one line of verse, however, the
hierarchical structure of XML means that quotation elements cannot span multiple
<l>
elements. In this case, you must use the
@next and
@prev attributes to connect the fragments of the quotation:
<lg><!-- … --> <l> <q xml:id="emd2H4_M_q_16" next="#emd2H4_M_q_17">Happy am I that have a man so bold</q> </l> <l> <q xml:id="emd2H4_M_q_17" prev="#emd2H4_M_q_16" next="#emd2H4_M_q_18">That dares do justice on my proper son</q> </l> <l> <q xml:id="emd2H4_M_q_18" prev="#emd2H4_M_q_17" next="#emd2H4_M_q_19">And no less happy having such a son</q> </l> <l> <q xml:id="emd2H4_M_q_19" prev="#emd2H4_M_q_18" next="#emd2H4_M_q_20">That would deliver up his greatness so</q> </l> <l> <q xml:id="emd2H4_M_q_20" prev="#emd2H4_M_q_19">Into the hands of justice.</q> You did commit me,</l> <!-- … --> </lg>
<lg><!-- … --> <l> <quote>Poor deer</quote>, quoth he, <quote xml:id="emdAYL_M_quote_3" next="#emdAYL_M_quote_4">thou mak’st a testament</quote> </l> <l> <quote xml:id="emdAYL_M_quote_4" prev="#emdAYL_M_quote_3" next="#emdAYL_M_quote_5">As worldlings do, giving thy sum of more</quote> </l> <l> <quote xml:id="emdAYL_M_quote_5" prev="#emdAYL_M_quote_4">To that which had too much</quote>. Then, being there alone,</l> <!-- … --> </lg>
Although split lines are also cases of fragmented pieces of the text being linked
together through encoding, we do not use
@next and
@prev to link split lines. Since split lines are so common, we developed a unique encoding
practice for them.
For split lines, we add the
@part attribute and one of three values, I, M, or F, to the
<l>
element wrapping the split line. The I, M, and F values stand for initial,medial, and final respectively and indicate the line’s position in the sequence of split lines:
LEMDO has created a few tools to make your encoding work easier. This documentation
will guide you through using our file templates and transformations. Another useful
tool (keyboard shortcuts) is documented in Keyboard Shortcuts and Special Characters.
You can use LEMDO’s file templates when creating new files for your edition. These
files are created and maintained by the LEMDO team to provide you with metadata, basic
file structure, necessary elements, and helpful information and documentation links
for the type of file that you are creating. For example, our critical paratext template
gives the metadata required for critical paratexts, sample
<div>
and
<p>
elements, and sample block quotes (using the
<cit>
and
<quote>
elements).
To create a file using a template, follow these steps:
At the top of your Oxygen window, click File and then select New from the drop down menu.
In the window that pops up, scroll down to the Framework templates folder. Click on the LEMDO subfolder. This will show you a list of the templates that we have created.
Select the template that you wish to use.
At the bottom of the New file window, select Save as. If you know the pathway down which you wish to save your file, you can type it into
the available field (i.e., lemdo/data/texts/{your edition abbreviation}/{the appropriate folder}). Otherwise, click on the folder to the right of the text field and browse for the
correct directory. Name your file according to LEMDO’s naming conventions.
Click Create.
Follow the instructions outlined in your newly created file. We use XML comments liberally
in template files to provide you with instructions and helpful tips. You may delete
comments as you complete the tasks therein.
Transformations
In addition to making templates to create new files, LEMDO has written XSLTs (eXtensible
Stylesheet Language Transformations) to help you complete encoding tasks. Some are
designed to create a new file from an existing one (e.g., our transformation to create
a baseline modernized text from semi-diplomatic transcriptions), while some are simply
meant to complete repetitive tasks (e.g., our transformation to number
<lb>
elements with @type="wln" in semi-diplomatic transcriptions). Regardless, these transformations are meant to
save you time and effort so that you can focus on other editorial tasks.
Step-By-Step: Run Transformations on Your Files
Running transformations is generally straightforward. Follow these steps:
In Oxygen’s project view, find the file that you wish to run a transformation on.
Right click on that file.
Hover your mouse over Transform.
Select Transform with…
Scroll down the list to find the transformation that you are interested in. Select
that transformation.
Click Apply selected scenarios (1). If there is a number greater than 1 in the parentheses on that button, your file
likely has other associated transformations. Generally, we do not want this. Unselect
any transformations that you do not want to run before clicking to apply the selected
scenarios.
Open the file on which you have run a transformation. Check that the transformation
has worked.
Validate your file.
Commit your file.
Example: Number Lines Using a Transformation
This example will show the process for running a transformation. It will number
<lb>
elements with a
@type value of wln in the file emdH4_F1.xml.
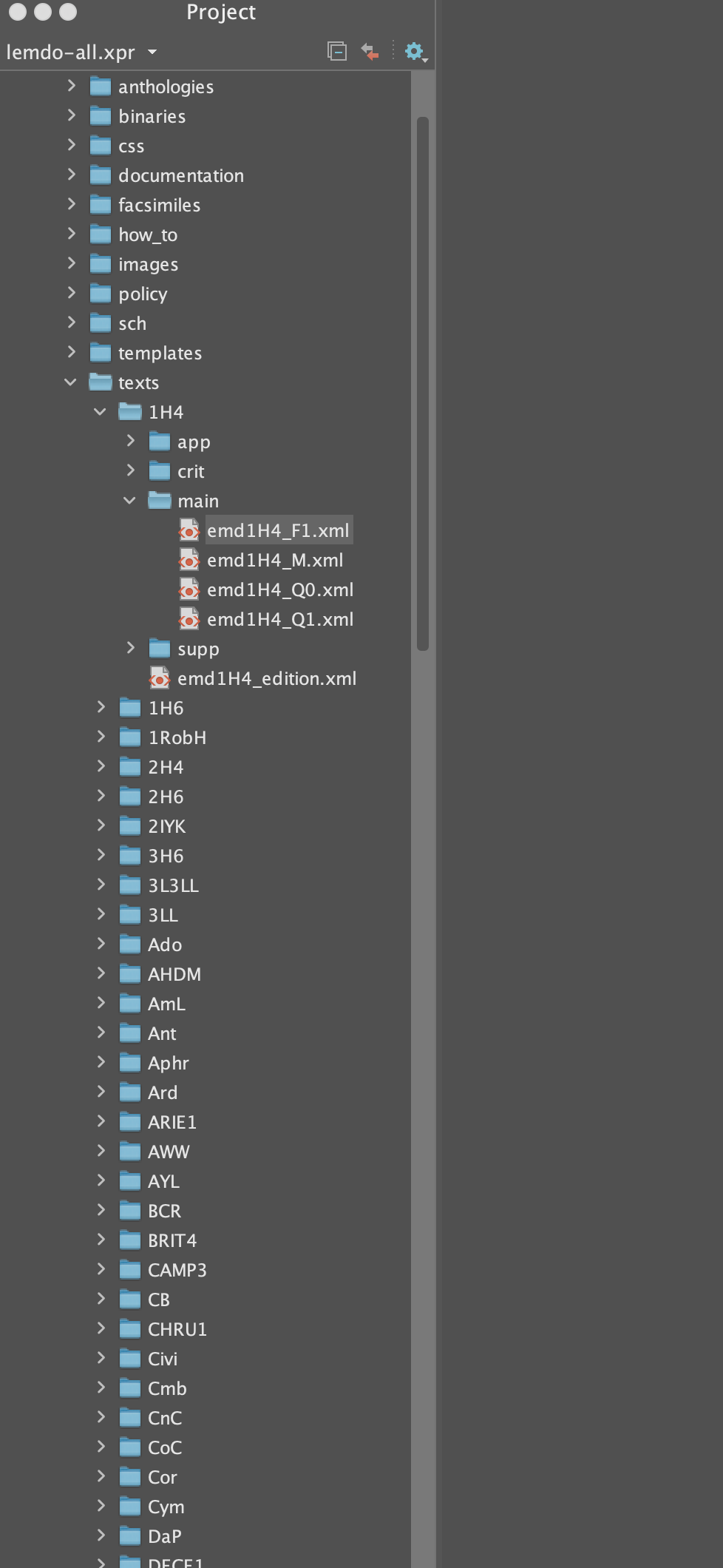
The first step is to right click on the file in Oxygen’s project view:
Here, we want to transform emd1H4_F1.xml, which lives in data/texts/1H4/main.
Next, hover over Transform and select Transform with…:
Note that we generally do not need to configure transformation scenarios for specific
files. This will permanently associate a specific transformation with the file that
you are working on. Most of the time, we need to use a transformation only once on
a file and we do not want it to be associated with the file long-term because we do
not want to repeatedly apply the same transformation.
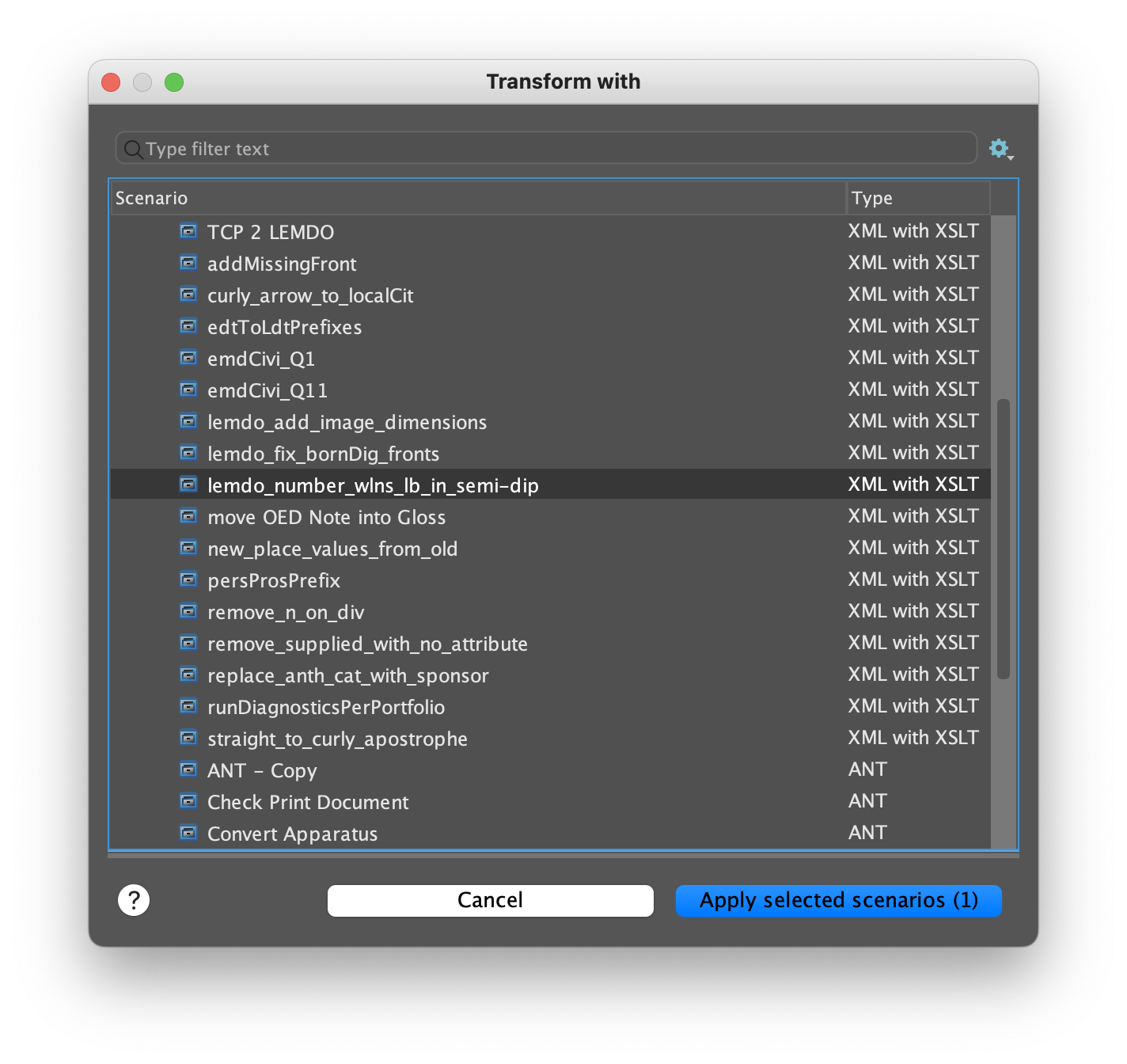
When you click Transform with…, a window will open allowing you to select the appropriate transformation:
In this case, we want to number line beginnings in a semi-diplomatic transcription,
so we will select lemdo_number_wlns_lb_in_semi-dip. If you are uncertain which transformation to use, or you want us to add a new transformation
to our list, please email lemdo@uvic.ca.
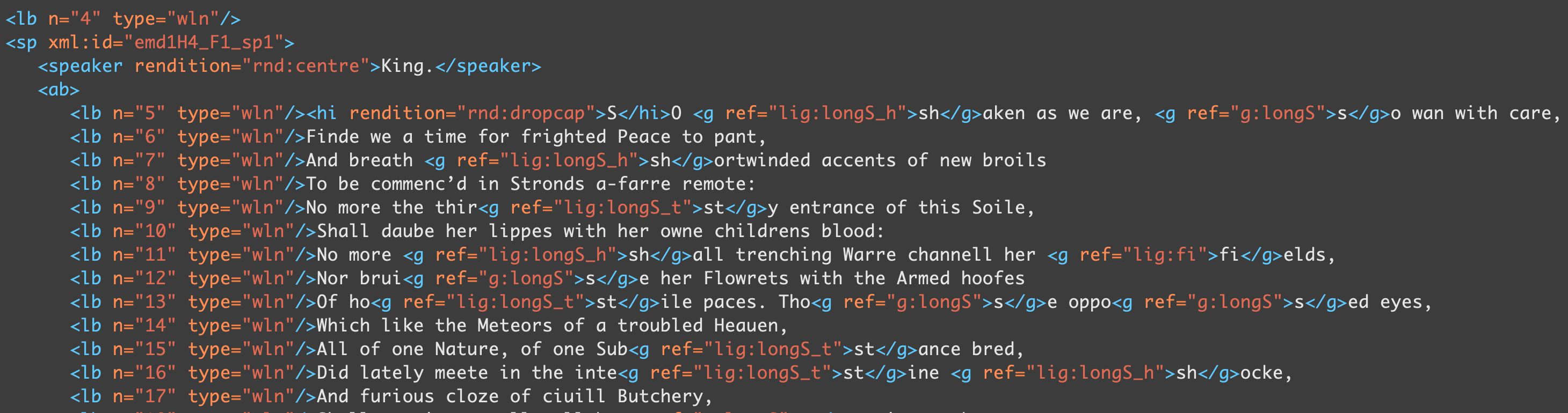
After clicking the Apply selected scenarios button, we open the file to check that the transformation has worked as expected:
The
<lb>
elements with @type="wln" now have consecutively numbered
@n attributes. The transformation has successfully worked as expected.
As always, the last step in Oxygen is to validate the file.
Notes
1.Note that for semi-diplomatic transcriptions, we give a numbered siglum (e.g., Q1,
F1) if there are more than one early editions. For plays with only one early edition,
we do not include a number in their sigla (e.g., Q, F).↑
2.Most anthologies do not require modernized title pages. Check with your anthology
lead.↑
4.These files are rooted on
<teiCorpus>
and have two
<teiHeader>
elements.↑
Prosopography
Illya
Illya has a BA in English and Sociocultural Anthropology and an MA in English. Prior
to joining the HCMC, he was a PhD candidate in English and Book History at the University
of Toronto and worked on Records of Early English Drama and on the Modernist Archives Publishing Project. His work at the HCMC focuses on creating web-based applications for research projects
led by members of the faculty of Humanities at the University of Victoria. This involves
creating schemas for new and existing datasets, writing XSLT and build files to transform
datasets into structured TEI and HTML formats, implementing staticSearch, and ensuring
that new projects are Endings Principles compliant.
Isabella Seales
Isabella Seales is a fourth year undergraduate completing her Bachelor of Arts in
English at the University of Victoria. She has a special interest in Renaissance and
Metaphysical Literature. She is assisting Dr. Jenstad with the MoEML Mayoral Shows
anthology as part of the Undergraduate Student Research Award program.
Janelle Jenstad
Janelle Jenstad is a Professor of English at the University of Victoria, Director
of The Map of Early Modern London, and Director of Linked Early Modern Drama Online. With Jennifer Roberts-Smith and Mark Beatrice Kaethler, she co-edited Shakespeare’s Language in Digital Media: Old Words, New Tools (Routledge). She has edited John Stow’s A Survey of London (1598 text) for MoEML and is currently editing The Merchant of Venice (with Stephen Wittek) and Heywood’s 2 If You Know Not Me You Know Nobody for DRE. Her articles have appeared in Digital Humanities Quarterly, Elizabethan Theatre, Early Modern Literary Studies, Shakespeare Bulletin, Renaissance and Reformation, and The Journal of Medieval and Early Modern Studies. She contributed chapters to Approaches to Teaching Othello (MLA); Teaching Early Modern Literature from the Archives (MLA); Institutional Culture in Early Modern England (Brill); Shakespeare, Language, and the Stage (Arden); Performing Maternity in Early Modern England (Ashgate); New Directions in the Geohumanities (Routledge); Early Modern Studies and the Digital Turn (Iter); Placing Names: Enriching and Integrating Gazetteers (Indiana); Making Things and Drawing Boundaries (Minnesota); Rethinking Shakespeare Source Study: Audiences, Authors, and Digital Technologies (Routledge); and Civic Performance: Pageantry and Entertainments in Early Modern London (Routledge). For more details, see janellejenstad.com.
Joey Takeda
Joey Takeda is LEMDO’s Consulting Programmer and Designer, a role he assumed in 2020
after three years as the Lead Developer on LEMDO.
Mahayla Galliford
Project Manager, 2025-present; Assistant Project Manager, 2024-2025; Research Assistant,
2021-present. Mahayla Galliford (she/her) graduated from the University of Victoria
with a BA (honours with distinction) in 2024, and an MA English in 2026. Mahayla’s
undergraduate research explored early modern stage directions and civic water pageantry.
Her SSHRC-funded MA thesis project focuses on transcribing, editing, and encoding
early modern girls’ manuscripts, specifically Lady Rachel Fane’s May Masque in collaboration with LEMDO.
Martin Holmes
Martin Holmes has worked as a developer in the UVic’s Humanities Computing and Media
Centre for over two decades, and has been involved with dozens of Digital Humanities
projects. He has served on the TEI Technical Council and as Managing Editor of the
Journal of the TEI. He took over from Joey Takeda as lead developer on LEMDO in 2020.
He is a collaborator on the SSHRC Partnership Grant led by Janelle Jenstad.
Navarra Houldin
Training and Documentation Lead 2025–present. LEMDO project manager 2022–2025. Textual
remediator 2021–present. Navarra Houldin (they/them) completed their BA with a major
in history and minor in Spanish at the University of Victoria in 2022. Their primary
research was on gender and sexuality in early modern Europe and Latin America. They
are continuing their education through an MA program in Gender and Social Justice
Studies at the University of Alberta where they will specialize in Digital Humanities.
Nicole Vatcher
Technical Documentation Writer, 2020–2022. Nicole Vatcher completed her BA (Hons.)
in English at the University of Victoria in 2021. Her primary research focus was women’s
writing in the modernist period.
Samuel Seaberg
Samuel Seaberg, a University of Victoria English undergrad, enjoys riding his bike.
During the summer of 2025, he began working with LEMDO as a recipient of the Valerie
Kuehne Undergraduate Research Award (VKURA). Unfortunately, due to his summer being
spent primarily in working to establish an edition of Thomas Heywood’s If You Know Not Me, You Know Nobody, Part 2 and consequently working out how to represent multi-text works in a digital space,
his bike has suffered severely of sheltered seclusion from the sun. Note: Samuel now
works for LEMDO as the Assistant Project Manager, much to his bike’s chagrin.
Si Micari-Lawless
Si Micari-Lawless is a research assistant with LEMDO and MoEML, and an incoming fourth-year
English major at the University of Victoria.
Tracey El Hajj
Junior Programmer 2019–2020. Research Associate 2020–2021. Tracey received her PhD
from the Department of English at the University of Victoria in the field of Science
and Technology Studies. Her research focuses on the algorhythmics of networked communications. She was a 2019–2020 President’s Fellow in Research-Enriched
Teaching at UVic, where she taught an advanced course on Artificial Intelligence and Everyday Life. Tracey was also a member of the Map of Early Modern London team, between 2018 and 2021. Between 2020 and 2021, she was a fellow in residence
at the Praxis Studio for Comparative Media Studies, where she investigated the relationships
between artificial intelligence, creativity, health, and justice. As of July 2021,
Tracey has moved into the alt-ac world for a term position, while also teaching in
the English Department at the University of Victoria.
Orgography
LEMDO Team (LEMD1)
The LEMDO Team is based at the University of Victoria and normally comprises the project
director, the lead developer, project manager, junior developers(s), remediators,
encoders, and remediating editors.