The documentation in this chapter is for all editors and encoders. It provides information
about LEMDO’s categories and taxonomies including those categories needed to trigger
specific processing, standard play IDs, and allowed values for placement of stage
directions in semi-diplomatic transcriptions.
Types of Categories
LEMDO TEI files are categorized along many different vectors:
Document type (primary source text, born digital information page, etc.).
Editorial treatment (semi-diplomatic, modern spelling, etc.).
Book format (broadside, folio, quarto, etc.).
Work type (play, prose, poetry, etc.).
Original digital source (ISE IML encoding, TCP encoding, XWiki file, etc.).
These taxonomies (along with others) are defined in the TAXO1.xml taxonomies file, and incorporated from there into the project schema. Then every
TEI document is assigned a number of
<catRef>
elements in its
<teiHeader>
:
This example specifies that the text is a modern spelling version of a play, and
its original digital source was an IML file from the Internet Shakespeare Editions
repository. Many of these categories are assigned automatically when files are converted,
but encoders are expected to check that they are correct and add any new categories
required. If
<catRef>
values are incorrect or missing, a document may not render correctly, or the wrong
Schematron rules may be triggered.
For full details of all LEMDO’s taxonomies, look at the Taxonomies page.
Additional Taxonomies
In addition to the categories that we use to classify our TEI files, there are a number
of other taxonomies that are documented in this chapter. While the categories described
above are used in the TEI header to ensure the correct processing is applied to files,
our other taxonomies are largely to ensure consistent encoding throughout the LEMDO
project.
Learning Outcomes
This chapter gives you all the information that you need to find and use values from
LEMDO’s taxonomies. By the time you have worked through every section of this chapter,
you will:
Understand and be able to update the categories (
<catRef>
elements) in your files’ TEI headers.
Be familiar with the audiences our documentation can be directed towards.
Know where to find our list of authority identifiers for bibliography and citation.
Know what each of our placement and rendition values should be used for in semi-diplomatic
transcriptions.
Have access to the lists of glyphs and ligatures that LEMDO has used for semi-diplomatic
transcriptions.
Learn about the ligatures that LEMDO has used in semi-diplomatic transcriptions (note
that we no longer encourage encoders to tag ligatures in new files)
Learn about the standard renditions that LEMDO has created to simplify inline styling
in semi-diplomatic transcriptions
Document Type Taxonomy
All documents in LEMDO are either born-digital documents or primary documents. Within those two general categories, LEMDO offers additional ways to categorize
a file.
Born-digital documents in an edition include: annotations, critical paratexts, bibliographies,
the edition landing page, and XML files containing instructions for generating the
print output. Born-digital documents in LEMDO-dev include documentation pages, landing
pages, databases, and programmatically generated pages. Born-digital files in an anthology
include pedagogy pages, landing pages, About pages (i.e., about the project/anthology), history pages (e.g., history of a playing
company), and information pages (e.g., copyright, citatation).
Primary documents in an edition include: facsimiles, semi-diplomatic transcription(s),
collations, primary paratexts (commendatory poems, prefatory matter, addresses to
the reader, alternate prologues), and modernized text(s). LEMDO-dev does not have
primary pages. An anthology might have primary documents that are not in an edition,
if the anthology chooses to present contextual documents relevant to the entire anthology
(e.g., a lease for a playhouse).
Every XML file must have a document type indicated in its
<teiHeader>
. Capture this information via the
<catRef>
element. The value of
@scheme is tax:emdDocumentTypes. The value of the
@target attribute is the relevant category within the Document Type Taxonomy. This example indicates that the file has the document type category cat:ldtPrimaryText.
<textClass> <catRef scheme="tax:emdDocumentTypes" target="cat:ldtPrimaryText"/> <!-- Normally, there will be other catRefs here to capture the other, intersecting
categories to which the document belongs. --> </textClass>
Born Digital
@xml:id
Name
Description
ldtBornDigAbout
About
Documents about LEMDO or another anthology.
ldtBornDigAboutPolicy
Policy
Documents about LEMDO policy or the policies of another anthology.
ldtBornDigDocumentation
Documentation
Encoding and editorial guidelines; programming, processing, and rendering instructions;
how-to instructions; element descriptions; and records of remediation.
ldtBornDigLanding
Landing
Landing pages.
ldtBornDigInfo
Information
Information pages.
ldtBornDigDatabase
Database
Entity collection files.
ldtBornDigGenerated
Generated
Files created automatically during the build.
ldtBornDigAnthology
Anthology
Anthology files (rooted on a
<teiCorpus>
element).
ldtBornDigEdition
Edition
Root files for textual editions.
ldtBornDigPrint
Print
Root files for print editions.
ldtBornDigParatext
Paratext
Ancillary files that typically form part of an edition, such as acknowledgements.
ldtBornDigParatextCritical
Critical
Critical material, such as a general introduction or a textual introduction.
ldtBornDigParatextBibl
Bibliography
Bibliographies and reference lists.
ldtBornDigParatextCharacters
Characters
Character lists and cast lists. Note that character lists for modernized texts belong
in the header of the modernized text, not in a separate file.
ldtBornDigParatextAnnotation
Annotation
Notes, glosses, and other annotations.
ldtBornDigParatextCollation
Apparatus
Collation files.
ldtBornDigParatextHist
History
Documents on historical background.
ldtBornDigParatextPedagogical
Pedagogy
Teaching notes, lesson plans, and other pedagogical material.
Primary
@xml:id
Name
Description
ldtPrimaryText
Primary Source Text
Edited primary source texts. Modernized texts and semi-diplomatic texts must have
this value. Not to be used for supplementary texts.
ldtPrimaryFacsimile
Facsimile
Files with
<facsimile>
pointing to digital surrogates.
ldtPrimaryParatext
Primary Paratext
Dedications, addresses, commendatory poems, and other primary source paratexts. Do
not use for EMDP. Use lpt values instead.
ldtTest
Test
Test-only document.
Work Type Taxonomy
LEMDO’s work type taxonomy allows us to capture the genre of our primary documents.
The work type triggers certain types of processing. The current list of work types
is short: play, poetry, prose, and mayoral show, and dramatic paratext. We are open
to adding new types as required for new anthologies.
Only documents that have the document type of primary (i.e., that have a value of
ldtPrimaryText) can have a work type. Capture this information via the
<catRef>
element. The value of
@scheme is tax:emdWorkTypes. The value of the
@target attribute is the relevant category within the Work Type Taxonomy. In the following example, note that the file has the document type primary and the
work type play.
<textClass> <catRef scheme="tax:emdDocumentTypes" target="cat:ldtPrimaryText"/> <catRef scheme="tax:emdWorkTypes" target="cat:lwtPlay"/> <!-- You will probably also have a catRef for editorial treatment. --> </textClass>
Work Types
@xml:id
Name
Description
lwtPlay
Play
Dramatic text, semi-diplomatic or modernized.
lwtPoetry
Poetry
Work which is primarily non-dramatic poetry.
lwtProse
Prose
Work which is primarily prose.
lwtShow
Mayoral Show
Mayoral show, semi-diplomatic or modernized.
lwtPara
Dramatic Paratext
Dramatic paratext transcribed for EMDP.
Print Book Formats Taxonomy
LEMDO’s print book format taxonomy allows us to capture the book format of the sources
we transcribe in the semi-diplomatic transcriptions. The book format type triggers
certain types of processing as well. The current list of book formats types is short:
broadside, folio, quarto, and octavo. We are open to adding new types as required
for new anthologies.
Only documents that have the document type value of ldtPrimary (or a subordinate primary document type such as ldtPrimaryText) and editorial treatment type of letSemiDiplomatic can have a book format type. Capture this information via the
<catRef>
element. The value of
@scheme is tax:emdBookFormats. The value of the
@target attribute is the relevant category within the Book Format Taxonomy.
Print volume constructed from sheets folded twice.
lbfOctavo
Octavo
Print volume constructed from sheets folded three times.
lbfManuscript
Manuscript
Manuscript.
lbfDuodecimo
Duodecimo
Duodecimo.
Editorial Treatments Taxonomy
LEMDO’s editorial treatment taxonomy allows us to indicate the general editorial treatment
the editor has applied to the text. The editorial treatment type triggers certain
types of processing as well. For example, some elements (e.g.,
<pb>
,
<fw>
) are allowed in texts given semi-diplomatic editorial treatment but not allowed in
texts given modernized editorial treatment. The current list of editorial treatments
is short: semi-diplomatic, modern, excerpted, and mixed.
Note that LEMDO created the mixed editorial treatment category (letMixed) to deal with legacy supplementary texts. New texts prepared on the LEMDO platform
are not allowed to have this editorial treatment. If anthologies choose to allow supplementary
texts in an edition, editors must follow either the modern editorial and encoding
guidelines or the semi-diplomatic editorial and encoding guidelines. Unless there
is some value in retaining semi-diplomatic (e.g., an excerpt from The Faerie Queene, in which spelling is semantically significant), supplementary texts should be modernized
because their primary purpose is pedagogical. Most supplementary texts will also be
excerpts, which means they will have the additional editorial treatment type of letExcerpted.
Only documents that have the document type value of ldtPrimary (or a subordinate primary document type such as ldtPrimaryText) can have an editorial treatment type. Capture this information via the
<catRef>
element. The value of
@scheme is tax:emdEditorialTreatments. The value of the
@target attribute is the relevant category within the Editorial Treatment Taxonomy.
A modern-spelling edition of a play would have the following
<catRef>
elements:
Texts in which original spelling and other features have been retained.
letModernized
Modernized
Texts that have been modernized according to a set of editorial principles.
letExcerpted
Excerpted
Texts which are not complete, usually because of editorial selection in service of
a specific goal.
letMixed
Mixed
Texts in which a variety of possibly incongruous editorial approaches have been mixed.
Use this category in combination with ldtPrimary.
Document Histories Taxonomy
LEMDO’s document history taxonomy allows us to indicate the history of a document
in cases where we have converted a file from some other source for use in the LEMDO
ecosystem. The current list of document history types is short: IML (anything we converted
from the ISE Markup Language), XWiki (anything we converted from XWiki, either directly
from XWiki files before the server failed or from staticized web pages of XWiki output),
TCP (anything we converted to LEMDO TEI P5 from EEBO-TCP’s TEI P4), MoEML (semi-diplomatic
transcriptions of mayoral shows for the MoMS anthology), and SQL (anything we created
from an SQL database).
Such converted files also undergo lengthy remediation. You will also use the
@status attribute on the
<revisionDesc>
element to track the progress of the remediation. See Document Status Taxonomy.
Only documents that have been converted and have a prior history in some other markup
language have a document history type. Capture this information via the
<catRef>
element. The value of
@scheme is tax:emdDocumentHist. The value of the
@target attribute is the relevant category within the Document History Taxonomy.
The following example gives the various
<catRef>
elements for the modernized text of a play that was first prepared in IML for the
old ISE platform:
This TEI file was created based on one or more files from the Internet Shakespeare
Editions anthology, originally encoded in ISE Markup Language (a custom markup language
somewhat resembling SGML).
edhSourceCBJ
Original Source: Cambridge Ben Jonson
This TEI file was created based on one or more files from the Cambridge Edition of
the Works of Ben Jonson Online (CEWBJO or CWBJO), originally encoded in different
customization of TEI.
edhSourceXWiki
Original Source: XWiki
This TEI file was created based on one or more supplementary files from the Internet
Shakespeare Editions anthology, originally encoded in HTML and stored in the ISE’s
XWiki system.
This TEI file was created from data originally captured in a SQL database structure.
Audiences Taxonomy
LEMDO’s audience taxonomy allows us to indicate the readership we have in mind when
we write documentation. The current list of imagined audiences is short: remediators,
encoders, editors, anthology leads, developers, repository users, and documenters.
Each of these audiences (except for documenters) also has a Quickstart page. (See
Introduction to Quickstart Guidelines.)
Audience types can be applied to the root element of a documentation file, i.e., the
root
<div>
element or any child
<div>
element. We do not apply the audience types to more deeply nested
<div>
elements.
Audience Types
@xml:id
Name
Description
audRemediator
Remediator
An encoder who has the responsibility of converting IML-encoded or TCP texts to the
LEMDO TEI P5 customization.
audEncoder
Encoder
Anyone who is encoding texts in the LEMDO TEI P5 customization.
audEditor
Editor
Anyone who is editing a play or related works for publication in a LEMDO anthology.
audAnthologyLead
Anthology Lead
Anyone who is responsible for a group of editors who are editing plays or related
works for publication in a LEMDO-generated anthology (e.g., the leads of MoMS, QME,
DRE, NISE).
audDeveloper
Developer
Anyone who is responsible for maintaining the repository, writing processing, running
builds, or customizing a CSS file for an anthology. Normally, developers are based
at UVic and work in the lemdo/code section of the repository. Anthology leads may
hire a developer/designer to customize a CSS file for an anthology.
audRepoUser
Repository User
Anyone who commits work to the LEMDO repository, including editors and RAs who have
write privileges on an edition portfolio.
audDocumenter
Documenter
Anyone who writes project documentation.
Document Status Taxonomy
LEMDO’s document status taxonomy allows us to track the progress of a file from creation
to publication. For converted files, the values allows us to track the progress of
the remediation. The document status value triggers different aspects of the schema.
For example, a document with the
@status value of IML-TEI will not trigger most of the schema and Schematron errors. The schema and Schematron
kick in only when you changed the
@status to IML-TEI_INP. This feature of LEMDO ensures that the files we commit, regardless of their state
of remediation or completion, are always valid according to the set of rules that
we apply.
Although it may seem redundant, we capture the status in two places whenever the status
changes:
On the
<revisionDesc>
element. The
<revisionDesc>
element captures the current status of the file.
On the
<change>
element. When the status of the file changes, add a
<change>
element with a
@who attribute for yourself, a
@when attribute for the date, and a
@status attribute for the new status.
The reason we have adopted this approach is that it allows us to keep track of the
date of all the status changes. Ultimately, we are most interested in the date of
publication so that future users can cite the page by its publication date.
A born-LEMDO file will normally go through the following status changes:
TEI_INP: give the document this value as soon as you create it and retain it as you work
on the file.
TEI_proofing: give the document this value when it is ready to be proofread and maintain it while
you proofread the file.
TEI_proofed: give the document this value once someone has finished proofing the document.
peerReviewed: give the document this value once it has been peer reviewed.
published: the LEMDO Team will give the document this value once they have determined (alongside
you and your anthology lead) that it is ready to be published in an anthology release.
For more information on publication, see Proofread and Change Status.
A file that was converted from EEBO-TCP will normally go through the following status
changes:
prgGenerated: give the document this value when you (a developer) run the conversion.
TCP-TEI: give the document this value as soon as you need to check it against the basic rules
in the LEMDO schema.
TCP-TEI_INP: give the document this value while you are working on bringing the document in line
with the full LEMDO schema. If you cannot achieve a valid file before you commit,
revert the document status back to TCP-TEI and validate again before you commit.
TCP-TEI_proofing: give the document this value when it is ready to be proofread and maintain it while
you proofread the file.
TCP-TEI_proofed: give the document this value once it has been proofread by another encoder or an
editor.
published: the LEMDO Team will give the document this value once they have determined (alongside
you and your anthology lead) that it is ready to be published in an anthology release.
A file that was converted from IML will go through the following status changes:
peerReviewed: give the document this status when you convert it, if the document had been peer
reviewed for the legacy anthology, with a date showing the last date by which it could
have been peer reviewed (the date of conversion or the date the old software failed,
whichever is earlier).
prgGenerated: give the document this status when you (a developer) convert it, with the date of
conversion.
IML-TEI: give the document this value as soon as you need to check it against the basic rules
in the LEMDO schema.
IML-TEI_INP: give the document this value while you are working on bringing the document in line
with the full LEMDO schema. If you cannot achieve a valid file before you commit,
revert the document status back to IML-TEI and validate again before you commit.
IML-TEI_proofing: give the document this value when it is ready to be proofread and maintain it while
you proofread the file.
IML-TEI_proofed: give the document this value once it has been proofread by another encoder or an
editor.
published: the LEMDO Team will give the document this value once they have determined (alongside
you and your anthology lead) that it is ready to be published in an anthology release.
In the example below, we show how we tracked the status of the conversion and remediation
of the modernized text of Famous Victories in the
<revisionDesc>
of emdFV_M. We know that the file was peer reviewed before 2018, when the ISE server failed.
Joey Takeda ran the conversion on 2018-07-11. Tracey El Hajj started to remediate
the file on 2020-07-10, work that took some time. Janelle Jenstad proofed the file
on 2020-12-03. On 2020-12-21, the file was published. The status of the file on the
<revisionDesc>
would have changed on each of those dates. Since
<revisionDesc>
shows only the most recent status, the
@status attribute on the
<change>
elements allows us to keep a history of the status changes.
<revisionDesc status="published"> <change who="pers:JENS1" when="2020-12-21" status="published">Regularized metadata. Licensed and published file.</change> <change who="pers:JENS1" when="2020-12-03" status="IML-TEI_proofed">Worked on the TEI header and proofed the document.</change> <change who="pers:ELHA1" when="2020-10-16">Added anchors and modified using XSLT.</change> <change who="pers:MATT2" when="2020-10-13">Specified quotations and removed Video headings.</change> <change who="pers:MATT2" when="2020-10-08">Updated Character List; removed compound characters and updated name elements and
information from emdFV_M_Characters.xml.</change> <change who="pers:ELHA1" when="2020-08-03">Added document xml:id to the ids throughout the file using XSLT.</change> <change who="pers:ELHA1" when="2020-07-13" status="IML-TEI_INP">Removed supplied elements that do not have attributes, using XSLT.</change> <change who="pers:ELHA1" when="2020-07-10" status="IML-TEI">Added status IML-TEI.</change> <change who="pers:TAKE1" when="2018-11-15">Added <gi>front</gi> with titlePart using XSLT.</change> <change when="2018-07-11" who="pers:TAKE1" status="prgGenerated">Created TEI from IML file.</change> <change who="org:QME1" notAfter="2018" status="peerReviewed">File prepared for QME and reviewed by QME. Prior history not known.</change> </revisionDesc>
Note that you can switch your document from IML-TEI_INP back to IML-TEI if you have not been able to achieve a fully valid document before you need to commit
your file and end your work session for the day. As long as the file is valid with
the
@status of IML-TEI, you may commit it.
Note on
@statuspublished and peerReviewed: LEMDO has anticipated that some parts of editions may be published before undergoing
peer review and that some parts of an edition may never undergo peer review (e.g.,
supplementary materials). LEMDO’s system is designed so that you can have a file published
first and peer reviewed later, or vice versa. The date of publication and the date
of peer review will be taken from the
@when attribute on the
<change>
element. The final status of the document can be either peerReviewed or published without implying anything about peer review or publication status.
Note on
@statusdraft: This status is for born-digital documents (i.e., documents with
<catDesc>
of ldtBornDig (or subordinate categories).
Note on
@statusempty: Do not use this value. We have a handful of empty files left over from the batch
conversion of IML files to TEI, to which we have given the status empty to help us find them. Once we have added the content from other sources, we will
deprecate this status. Normally, there is no good reason to create an empty file.
Most of the time, you will have at least some content to add right away or a template
in place. Consult with the LEMDO team at UVic if you do want to create an empty file.
Document Status Values
@xml:id
Name
Description
prgGenerated
Programmatically Generated
Files that are programmatically generated using xslt. Most such files are documentation
or apparatus files.
published
Published
Files that have been published.
publishedWithPeerReview
Published with peer review
Files that have been published after being peer-reviewed.
publishedWithoutPeerReview
Published without peer review
Files that have been published before being peer-reviewed.
peerReviewed
Peer-reviewed
Files that have been peer reviewed.
draft
Draft
Files that are being drafted.
empty
Empty
Files that are empty (have no content other than a minimal TEI Header).
deprecated
Deprecated
This document is no longer relevant or has been superseded, but is being preserved
as part of LEMDO’s digital archive.
IML-TEI
IML to TEI
The text has been programmatically converted from IML to LEMDO TEI via a series of
transformations. The file is a .xml file. There are stray IML tags in these texts
that we retain until we have proofed the TEI. The transcription may have been checked
by an ISE editor but LEMDO has not yet checked it.
IML-TEI_INP
IML-to-TEI In Progress
The programmatic conversion is in the process of being carefully checked and remediated
by a LEMDO team member. The file is a .xml file.
IML-TEI_proofing
IML-to-TEI Ready for Proofing
The fully remediated file is ready for proofing or in the process of being proofed
by a LEMDO team member, editor, or anthology lead.
IML-TEI_proofed
IML-to-TEI Proofed
The programmatic conversion has been carefully checked and fully remediated by a LEMDO
team member and/or an editor or anthology lead. The file is now ready for peer review
(or for publication without peer review).
TCP-TEI
TCP-to-TEI
The text has been programmatically converted from TCP TEI P4 to LEMDO TEI (P5) via
a series of transformations. The file is a .xml file. The transcription is only as
correct as the underlying TCP transcription (which contains gaps, errors, and normalized
long “s” characters). The TCP metadata is retained. This category is only for documents
that also have the document type ldt:primary (but not ldt:primaryModern).
TCP-TEI_INP
TCP to TEI In Progress
The text has been programmatically converted from TCP TEI P4 to LEMDO TEI (P5) via
a series of transformations. The file is in the process of being carefully corrected,
remediated, and proofed by a LEMDO team member. The file is a .xml file. This category
is only for documents that also have the document type ldt:primary.
TCP-TEI_proofing
TCP-to-TEI Ready for Proofing
The fully remediated file is ready for proofing or in the process of being proofed
by a LEMDO team member, editor, or anthology lead.
TCP-TEI_proofed
TCP to TEI Proofed
This semi-diplomatic text has been programmatically converted from TCP TEI P4 to LEMDO
TEI (P5) via a series of transformations and carefully corrected, remediated, and proofed by a LEMDO team member. The file is
a .xml file. The transcription has been corrected; gaps have been supplied; the long
s has been restored. The TEI tagging has been checked and corrected by a LEMDO team
member. This category is only for documents that also have the document type ldt:primary.
TEI_INP
TEI in Progress
The text is being encoded in TEI.
TEI_collating
TEI Collation in Progress
A modernized text has been created from other sources, but has not yet been remediated
to fix e.g. capitalization issues or speech prefixes.
TEI_proofing
TEI Ready for Proofing
The fully remediated file is ready for proofing or in the process of being proofed
by a LEMDO team member, editor, or anthology lead.
TEI_proofed
TEI Proofed
The text is finished in TEI and proofed.
Responsibilities Taxonomy
Because LEMDO is committed to the Collaborators’ Bill of Rights and the Student Collaborators’ Bill of Rights (see LEMDO Ethos), we have an extensive taxonomy of responsibilities that allow you to give credit
in specific ways to everyone who contributed in any way to a file. We use the same
method to give credit to the early modern authors and printers.
We have used the Library of Congress MARC Code List for Relators (MARC relators) taxonomy
as much as possible. See https://www.loc.gov/marc/relators/relaterm.html. The LoC has occasionally added MARC relators at our request (e.g., mrk was a new
addition to capture the role of the encoder or markup editor). In other cases, where
there is no MARC relator for the responsibility we need to capture, we have created
a value of our using the same principle of three letters representing an abbreviation
of the full role name.
We give credit via a
<respStmt>
in the
<titleStmt>
of the
<teiHeader>
. You need the name and xml:id of the person responsible. You need the value that
best describes their role from the responsibility taxonomy. Finally, you need a phrase
for the text node of the
<resp>
element.
In this example, we indicate that a play is by Thomas Heywood:
Note on the text node of the
<resp>
element: This is a free text field. LEMDO encourages anthologies to develop their
own standardized wording for different types of work but does not currently have any
diagnostics to ensure consistency across an anthology.
Responsibility Values
@xml:id
Name
Description
aut
Author
MARC Code List for Relators definition: A person, family, or organization responsible
for creating a work that is primarily textual in content, regardless of media type
(e.g., printed text, spoken word, electronic text, tactile text) or genre (e.g., poems,
novels, screenplays, blogs). Use also for persons, etc., creating a new work by paraphrasing,
rewriting, or adapting works by another creator such that the modification has substantially
changed the nature and content of the original or changed the medium of expression.
LEMDO uses the term author in two contexts: (1) to indicate the author of a primary
work or document (such as Hamlet), and (2) to indicate the author of a secondary text (such as the Critical Introduction to Hamlet, by David Bevington).
aut_attrib
Supposed Author
MARC Code List for Relators definition: An author, artist, etc., relating them to
a resource for which there is or once was substantial authority for designating that
person as author, creator, etc. of the work.
LEMDO usage aligns with that of MARC.
bsl
Bookseller
MARC Code List for Relators definition: A person or organization who makes books and
other bibliographic materials available for purchase. Interest in the materials is
primarily lucrative.
LEMDO uses the term bookseller only in the metadata for publications and copies. In
cases where a publication was issued with variant title pages, list all booksellers
in all variant states of the title page.
csl
Consultant
MARC Code List for Relators definition: A person or organization relevant to a resource,
who is called upon for professional advice or services in a specialized field of knowledge
or training.
Consultant or Technical Advisor: A person who is called upon for professional advice
during the editorial and/or encoding processes. Give a person a credit in the edition
page if their role is more than one would list in the Acknowledgements page. LEMDO
uses this value for a technical advisor who provides training, answers questions,
and advises on encoding matters.
edt
Editor
MARC Code List for Relators definition: A person, family, or organization contributing
to a resource by revising or elucidating the content, e.g., adding an introduction,
notes, or other critical matter. An editor may also prepare a resource for production,
publication, or distribution. For major revisions, adaptations, etc., that substantially
change the nature and content of the original work, resulting in a new work, see author.
LEMDO uses the general term editor only in edition metadata and only to indicate when
a person is responsible for editing all parts of an edition. Otherwise, use the more
granular terms to describe the precise nature of the editorial role.
edt_asstcoord
Assistant Coordinating Editor
This term is for use in project-level or edition-level credits if an anthology’s organizational
structure includes this role. The term assistant coordinating editor appears in the
metadata for documents produced before 2017. From 2017 on, this term is reserved for
project-level credits. Do not use at the file level; if an assistant coordinating
editor performs a specific function with respect to a file, use the precise resp value
for their work.
edt_assoccoord
Associate Coordinating Editor
This term is for use in project-level or edition-level credits if an anthology’s organizational
structure includes this role. The term assistant coordinating editor appears in the
metadata for documents produced before 2017. From 2017 on, this term is reserved for
project-level credits. Do not use at the file level; if an associate coordinating
editor performs a specific function with respect to a file, use the precise resp value
for their work.
edt_assoctext
Associate Textual Editor
This term is for use in project-level or edition-level credits if an anthology’s organizational
structure includes this role. The term associate textual editor appears in the metadata
for documents produced before 2017. From 2017 on, this term is reserved for project-level
credits. Do not use at the file level; if an associate textual editor performs a specific
function with respect to a file, use the precise resp value for their work.
cont
Generic Contributor
Legacy term. Do not use: This is a generic category LEMDO uses when we have been unable to determine a more
precise role for this person. All generic contributors should be replaced by a more
specific value when/if we learn more information.
edt_cont
Contributing Editor
A contributing editor makes a significant contribution to an edition. LEMDO uses this
term to give credit to editors who have passed on their work (through choice, retirement,
or death) to a new editor or editorial team. If the new editor retains or revises
any of the original editor’s work, LEMDO acknowledges the original editor’s input
via this resp value.
edt_sup
Supervising Editor
An editor who supervises the work of a student editor.
edt_coord
Coordinating Editor
Some anthologies have one or more coordinating editor. Use this value in responsibility
statements on an edition title. Normally, anthologies should not list coordinating
editors or general editors on every XML file in an edition.
edt_cpy
Copy Editor
LEMDO uses the term owner for the person who checks facts, quotations, and citations;
may make formatting changes; may convert from one citation style to another; may suggest
wording changes; and enforces conformity with the project style guide.
edt_gen
General Editor
This term is for use in project-level or edition-level credits if an anthology’s organizational
structure includes this role. The term general editor appears in the metadata for
documents produced before 2017. From 2017 on, this term is reserved for project-level
credits. Do not use at the file level; if an general editor performs a specific function
with respect to a file, use the precise resp value for their work.
edt_gentext
General Textual Editor
This term is for use in project-level or edition-level credits if an anthology’s organizational
structure includes this role. The term general textual editor appears in the file-level
metadata for documents produced before 2017. From 2017 on, this term is reserved for
project-level credits. Do not use at the file level; if an general textual editor
performs a specific function with respect to a file, use the precise resp value for
their work.
edt_genperf
General Editor (Performance)
A person responsible for the performance strategy and methodology of a project.
man
Project Manager
A person responsible for managing the LEMDO project or a project within the LEMDO
suite of anthologies.
edt_mrk
Markup Editor
MARC Code List for Relators definition: A person or organization performing the coding
of SGML, HTML, or XML markup of metadata, text, etc.
LEMDO uses this term for someone who encodes a file, remediates a converted text,
or reviews the XML markup of a file.
edt_perf
Performance Editor
This term is for use in project-level or edition-level credits if an anthology’s organizational
structure includes this role. The term performance editor appears in the file-level
metadata for documents produced before 2017. From 2017 on, this term is reserved for
project-level credits. Do not use at the file level; if a performance editor performs
a specific function with respect to a file, use the precise resp value for their work.
edt_text
Textual Editor
This term is for use in project-level or edition-level credits if an anthology’s organizational
structure includes this role. The term textual editor appears in the file-level metadata
for documents produced before 2017. From 2017 on, this term is reserved for project-level
credits. Do not use at the file level; if a textual editor performs a specific function
with respect to a file, use the precise resp value for their work.
prn
Production Company
MARC Code List for Relators definition: An organization that is responsible for financial,
technical, and organizational management of a production for stage, screen, audio
recording, television, webcast, etc.
LEMDO uses this term for a group that performs a play or makes a film version of a
play. Example: Lord Denney’s Players.
edm
Video Editor
MARC Code List for Relators definition: A person, family, or organization responsible
for assembling, arranging, and trimming film, video, or other moving image formats,
including both visual and audio aspects.
LEMDO uses this term for a person who edits the video of a stage performance or edits
a film version of a play.
pbd
Anthology Lead
MARC Code List for Relators definition: A person or organization who presides over
the elaboration of a collective work to ensure its coherence or continuity. This includes
editors-in-chief, literary editors, editors of series, etc.
A person who presides over the creation of an anthology on the LEMDO platform, a role
that includes commissioning editions, approving proposals, supporting editors, arranging
for peer review, and liaising with the LEMDO team.
ptr
Printer
MARC Code List for Relators definition: A person, family, or organization involved
in manufacturing a manifestation of printed text, notated music, etc., from type or
plates, such as a book, newspaper, magazine, broadside, score, etc.
LEMDO uses this term for an early modern printer and for a publisher who is also a
printer. For booksellers who are not also printers, use the term bookseller.
rtm_ra
Editorial Research Assistant
MARC Code List for Relators definition: A person who participated in a research project
but whose role did not involve direction or management of it
Legacy term. Use rtm or appropriate role from 2017 on.
rtm
Research Team Member
MARC Code List for Relators definition: A person who participated in a research project
but whose role did not involve direction or management of it.
LEMDO uses this term for someone who contributes intellectual work but is not an RA.
scr
Scribe
MARC Code List for Relators definition: A person who is an amanuensis and for a writer
of manuscripts proper.
LEMDO uses this term to credit the person who copies a manuscript or prepares a fair
copy of it. Hands can be described in the HAND1 file.
trl
Translator
MARC Code List for Relators definition: A person or organization who renders a text
from one language into another, or from an older form of a language into the modern
form.
LEMDO usage aligns with that of MARC.
pdr
Project Director
MARC Code List for Relators definition: A person or organization with primary responsibility
for all essential aspects of a project, has overall responsibility for managing projects,
or provides overall direction to a project manager.
LEMDO uses the term project director for the person who directs the LEMDO project.
For anthology leads, use pbd.
drt
Director
MARC Code List for Relators definition: A person responsible for the general management
and supervision of a filmed performance, a radio or television program, etc.
LEMDO uses the term director for the person who manages or supervises a performance. We do not use it for project
level directors.
pfr
Proofreader
MARC Code List for Relators definition: A person who corrects printed matter.
LEMDO uses the term proofreader for the person who performs minor corrections to a
finalized document, which usually include typographical or rendering fixes. For copy-editing,
use resp:edt_cpy.
own
Owner
MARC Code List for Relators definition: A person, family, or organization that currently
owns an item or collection, i.e., has legal possession of a resource.
LEMDO uses the term owner for the person, family, or library that owns the physical
copy of an artifact reproduced in facsimile on the platform. The owner is often but
not necessarily the copyright holder.
vet
Peer Reviewer
LEMDO uses the term peer reviewer for a person who reviews a transcription, critical
materials, dataset, and/or some or all components of an edition.
cph
Copyright Holder
MARC Code List for Relators definition: A person or organization to whom copy and
legal rights have been granted or transferred for the intellectual content of a work.
The copyright holder, although not necessarily the creator of the work, usually has
the exclusive right to benefit financially from the sale and use of the work to which
the associated copyright protection applies.
Normally the editor is the copyright holder for an LEMDO edition.
edt_comp
Compiler
MARC Code List for Relators definition: A person, family, or organization responsible
for creating a new work (e.g., a bibliography, a directory) through the act of compilation,
e.g., selecting, arranging, aggregating, and editing data, information, etc.
LEMDO uses the term compiler for the person who chooses and aggregates the resources
included in an edition, if those resources are not all by the editor of the edition.
The compiler and the editor may be the same person; in that case, the person needs
two responsibility statements.
aut_ann
Author of Annotations
MARC Code List for Relators definition: A person or organization responsible for the
commentary or explanatory notes about a text.
LEMDO uses the term author of annotations for a person who writes annotions for a
text.
ann
Annotator
MARC Code List for Relators definition: A person who makes manuscript annotations
on an item.
aut_col
Collator
A person who compiles the vertical collations for a text.
anl
Analyst
MARC Code List for Relators definition: A person or organization that reviews, examines,
and interprets data or information in a specific area.
LEMDO usage aligns with that of MARC.
prg
Programmer
MARC Code List for Relators definition: A person, family, or organization responsible
for creating a computer program.
LEMDO usage aligns with that of MARC.
trc
Transcriber
MARC Code List for Relators definition: A person, family, or organization contributing
to a resource by changing it from one system of notation to another.
LEMDO uses transcriber to describe those that transcribe the text from a digital surrogate
of an early modern text into a semi-diplomatic transcription and for those that do
significant work in correcting and encoding the transcription of an early modern work.
wtm
Technical Writer
MARC Code List for Relators definition: Writer of Technical Material: A person responsible
for writing or compiling documentation of the project’s editorial, encoding, and programming
practices.
LEMDO usage aligns with that of MARC.
IDNO Authorities Taxonomy
Part of LEMDO’s long-term linking strategy is to create links to stable projects that
offer URIs for their resources. For many projects, the identification number of a
resource or catalogue entry forms the basis of the project’s URIs and ultimately URLs
to which we can link. In TEI, we wrap identification numbers in the
<idno>
element. IDNOs that we capture include DEEP numbers, DOIs, ISBNs, STC numbers, GitHub
numbers, and others.
The old URI of a webpage that has disappeared or is soon to be deprecated. Use in
the sourceDesc for remediated ISE, DRE, QME, CWBJO, B&F, and EMDP texts, and in other
contexts where the old URI might be useful. The value of recording old URIs is not
just historical; sometimes these webpages have been captured by the Wayback Machine.
Providing the old URI means that users can search for the webpage in the Wayback Machine.
LEMDO
LEMDO
The current canonical URI of a modern edition of a play on the LEMDO site. This is
used in the print edition of a play to provide a URL for readers to go from print
to online.
The sigla for a bibliographic item in the collation
STC
STC
Short Title Catalogue
TCP
TCP
Text Creation Partnership
URI
URI
Universal Resource Identifier
Wing
Wing
Wing
WSB
WSB
World Shakespeare Bibliography
Prefix Definitions Taxonomy
LEMDO uses prefixes as a kind of shorthand across the project so that you do not have
to type full pathways and URLs when you want to point to something inside or outside
the project using a
<ref>
element. When we build an HTML page from your XML, we replace the prefix with the
part of the URL that comes before the forward slash. So mol becomes “https://mapoflondon.uvic.ca/.” Prefixes are always followed by a colon and
then the unique identifier for the resource within the project to which we wish to
point.
A prefix is an abbreviation for the predictable part of a Uniform Resource Indicator
(URI). A prefix allows us to point easily to unique resources (URIs) within a digital
project (e.g., documents, entities, entries, sections of documents) without having
to repeat the predictable part of the URI. For example, the Map of Early Modern London’s (MoEML’s) URIs all begin with https://mapoflondon.uvic.ca/. We often point to MoEML resources from LEMDO editions. The full URI of those resources
would clutter up our encoding. Instead, we use the prefix mol. When LEMDO’s static HTML pages are built from the underlying encoding, the processing
instructions in the LEMDO taxonomy turn mol into https://mapoflondon.uvic.ca. We use prefixes to point to heavily used resources in our own project, such as the
Personography and Bibliography, as well as to a few stable resources outside our project.
As long as a project has predictable URIs that are constructed of a stable path plus
a unique ID, we can use prefixes and the unique ID to point directly to that resource.
Our encoding is thus efficient and consistent: doc:lemdo_about yields a link to https://lemdo.uvic.ca/lemdo_about.html; mol:CHEA2 yields a link to https://mapoflondon.uvic.ca/CHEA2.htm. This method of pointing is compatible with Linked Open Data applications and will
help LEMDO connect its data to other datasets in the future.
Prefix
Match pattern
Replacement pattern
Description
anth
(.+)
$1.xml
anth allows us to point to an anthology document in LEMDO’s XML collection.
aud
(.+)
TAXO1.xml#$1
aud allows us to point to a defined taxonomy of audiences in LEMDO.
beed
(.+)
BEED1.xml#$1
beed is used for witness and citation references to entries in the Bibliography of Editions
of Early English Drama (BEEED).
bibl
(.+)
BIBL1.xml#$1
bibl is used for bibliographic citations or witness references.
bin
(.+)\.pdf
binaries/$1.pdf
bin points to a binary file such as a PDF in the binaries folder in the eventual output
site. The file could be in any subfolder of the data/binaries folder at encoding
time. As of decision 2023-01, only PDFs with a lower-case extension are allowed.
cat
(.+)
TAXO1.xml#$1
cat denotes a pointer to a category in one of LEMDO’s taxonomies.
deep
(.+)
https://deepplaybooks.org/$1
deep points to a record in the Database of Early English Playbooks (DEEP).
doc
([\w\._-]+)(#.+)?
$1.xml$2
doc points to a LEMDO document by its xml:id or to a structural element with an xml:id
within a LEMDO document (e.g., a
<div>
element, a speech, or paragraph).
ebba points to a citation record in the Early English Ballads Archive (EBBA).
edimg
(.+)
https://lemdo.uvic.ca/editionImages/$1
edimg is an alternative to the above; when an edition uses many images, it is not appropriate
to sore them in the svn repository, so they are stored on /home1t/hcmc/www/lemdo/editionImages/.
The remainder of the path from that root must be included in the link.
edt
(.+)
TAXO1.xml#$1
edt allows us to point to a defined taxonomy of document types in LEMDO .
estc
(.+)
http://estc.bl.uk/$1
estc points to the URI for a single entry in the English Short Title Catalogue.
facs
^([^\|]+)\|(\d+)$
facs_$1.xml#facs_$1_$2
The facs prefix points to a surface element in a facsimile file.
g
(.+)
TAXO1.xml#g_$1
g denotes a glyph or other special character defined in the taxonomies document.
gb
(.+)
https://books.google.ca/books?id=$1
gb points to the unique URL for a single item in Google Books .
gloss
(.+)
GLOSS1.xml#$1
gloss allows us to link a term element to LEMDO’s centralized glossary .
hand
(.+)
HAND1.xml#$1
hand allows us to point to a single
<handNote>
in LEMDO’s centralized handNotes document. .
img
(.+)
images/$1
img points to an image in the images folder in the eventual output site. The image could
be in any of many images folders inside the data folder at encoding time.
ldt
(.+)
TAXO1.xml#$1
ldt denotes LEMDO’s document type taxonomy and categories therein.
leme points to the URI for a single entry in Lexicons of Early Modern English.
lew
(.+)
lew:$1
lew (= lazy editor witness) is required because the majority of collation apparatus elements inherited from
old projects did not have properly-defined witness lists, and just used plain text
identifiers instead. This prefix is used to signify that the text still needs a
<witList>
element and for the identifiers to be reconfigured appropriately.
lig
(.+)
TAXO1.xml#lig_$1
lig denotes a ligature defined in the taxonomies document.
marc points to a URI in the Library of Congress MARC Code List of Relators .
mol
([^#]+)(#.+)?
https://mapoflondon.uvic.ca/$1.htm$2
mol allows us to point to the URI of a single entity (location, person, bibliography
entry) in the Map of Early Modern London.
not
(.+)
BIBL1.xml#$1
not is essentially the reverse of the bibl prefix. It is used to point to an item through
the
@corresp attribute to signify that the two items are distinct; in other words, although they
may seem to be identical, they are in fact distinct.
or
(.+)
sch/lemdo.odd#$1
or stands for ODD Responsibility, and it allows us to point from a
@resp attribute on a documentation file or an element in one to a specific
<respStmt>
in the lemdo.odd file.
org
(.+)
ORGS1.xml#$1
org allows us to point to a single organization in LEMDO’s centralized orgography .
perf
^([^\|]+)\|(.+)$
performances/perf_$1.xml#perf_$1_$2
The perf prefix points to a scene in a performance.
pers
(.+)
PERS1.xml#$1
pers allows us to point to the bio-bibliographical entry for a single person in LEMDO’s
centralized personography .
prod
(.+)
PROD1.xml#$1
prod allows us to point to an entry in LEMDO’s centralized production file .
pros
(.+)
PROS1.xml#$1
pros allows us to point to a single historical person in LEMDO’s centralized prosopography
.
resp
(.+)
TAXO1.xml#$1
resp allows us to point to a single role in the defined taxonomy of LEMDO responsibilities
.
rnd
(.+)
TAXO1.xml#rnd_$1
rnd is used to reference specialized styling instructions.
role
^emd([^_]+)_([^_]+)_(.+)$
emd$1_$2.xml#emd$1_$2_$3
role points to the id of a
<person>
in a
<listPerson>
in the
<particDesc>
of a play file. Downstream, this person will be harvested into the containing file’s
appendix. Meanwhile, we try to construct the full path.
simple allows us to point to a predefined vocabulary of rendition types determined by the
TEI-Simple working group. Documentation for TEI Simple can be found here: http://www.tei-c.org/Vault/P5/3.3.0/xml/tei/Exemplars/tei_simplePrint.odd
.
sip is used to reference an artifact in the Shakespeare in Performance database. This link will be changed once SIP artifacts are moved to another institution.
sourcefacs
(.+)
https://lemdo.uvic.ca/facsimiles/$1
sourcefacs is used to reference an external image.
sourceperf
(.+)
https://lemdo.uvic.ca/videos/$1
sourceperf is used to reference an external video as used for performance editions.
static
(.+)
https://internetshakespeare.uvic.ca/$1
Not to be used by encoders! This is a static resource; this link will be changed once file storage has been resolved.
tax
(.+)
TAXO1.xml#$1
tax denotes a pointer to one of LEMDO’s taxonomies.
wsb
(.+)
https://www.worldshakesbib.org/entry/$1
wsb points to the URI for a single entry in the World Shakespeare Bibliography.
Placement Taxonomy
LEMDO’s placement taxonomy allows us to capture where something appears on the printed
or manuscript page of the sources we transcribe in semi-diplomatic transcriptions.
Note that some values may be used for both print and manuscript sources, some values
may be used only for print sources, and some values may be used only for manuscript
sources.
Placement Values
@xml:id
Name
Description
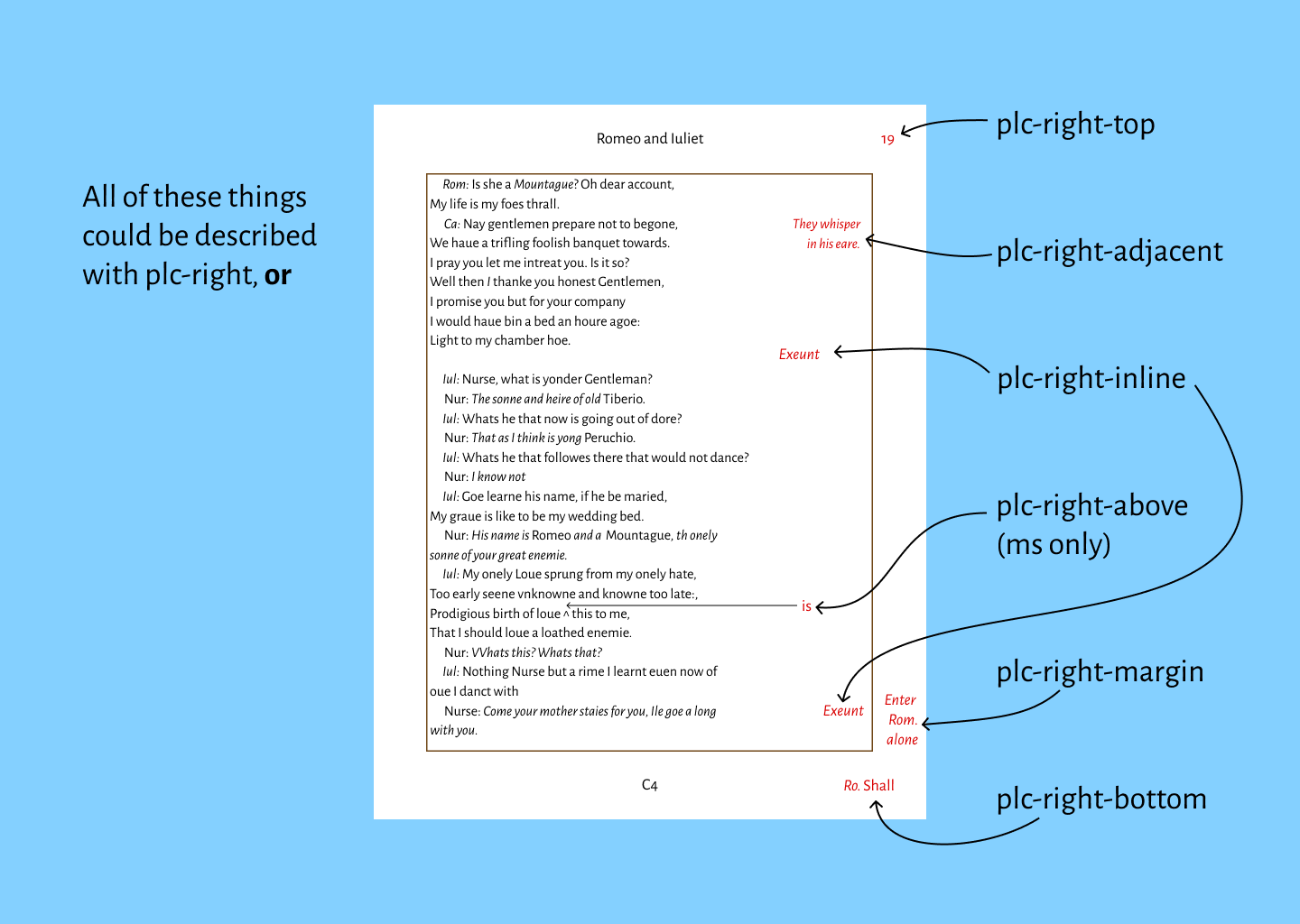
plc-right
Right / Droite
A generic place value for anything to the right of the text or a figure, or on the
right side of an otherwise empty line (in print) or space (in manuscript). Use this
value for transcriptions of print or manuscript texts if your anthology is not using
the more granular values of right-margin, right-inline, right-adjacent, right-top,
and right-bottom. Allowed in print and manuscript texts.
Emplacement par défaut à la droite du texte ou d’une image, ou à la droite à la fin
d’une ligne vide dans un livre imprimé / d’un espace vide dans un manuscrit. A utiliser
pour la transcription d’un texte imprimé ou manuscrit si l’anthologie n’utilise pas
les valeurs plus spécifiques de: marge-droite, intégré-droite, adjacent-droite, haut-droite,
bas-droite. Autorisé pour les imprimés et les manuscrits.
plc-right-margin
Right Margin / Marge-droite
In the right margin. For print texts, the right margin is a formal area to the right
of the text block. For manuscripts, use your judgement about what constitutes the
marginal area. Allowed in print and manuscript texts.
Dans la marge droite. Pour les textes imprimés, la marge droite définit la zone à
la droite du bloc de texte. Ce qui constitue la marge dans le cas des manuscrits est
à l’appréciation de l’éditeur. Autorisé pour les imprimés et les manuscrits.
plc-right-inline
Right Inline (Print) / Intégré-droite (Imprimé)
Within a compositorial line of a printed text and aligned to the right margin. Allowed
only in print texts and in manuscript texts that are modelled on printed pages.
Dans le corps du texte imprimé et aligné sur la marge droite. Autorisé seulement pour
les imprimés.
plc-right-adjacent
Right Adjacent / Adjacent-droite
Beside a speech or other literary division, inside the text block (printed texts)
or close to the main text (manuscript) but not in the margin. Use this value for interjections,
simultaneous speeches, and floating stage directions that span multiple lines. Allowed
in print and manuscript texts.
A côté d’une réplique ou d’une autre division du texte, à l’intérieur du bloc de texte
pour les imprimés, et à côté du texte principal pour les manuscrits, mais pas dans
la marge. Valeur à utiliser pour les interjections, les répliques simulténées et les
didascalies flottantes qui se poursuivent sur plusieurs lignes. Autorisé dans les
manuscrits et imprimés
plc-right-top
Right Top / Haute-droite
At the top right of the page. For print texts, the top is the forme work area. For
manuscripts, use your judgement about what constitutes the top of the page. For print
folio collections, use this value to indicate placement of page numbers. For manuscripts,
use this value to indicate placement of foliation numbers. Allowed in print and manuscript
texts.
Dans la marge supérieure à droite. Pour les imprimés, il s’agit du blanc de tête.
A l’appréciation de l’éditeur pour les manuscrits. Pour les imprimés, utiliser cette
valeur pour indiquer le placement de la pagination. Pour les manuscrits, utiliser
cette valeur pour indiquer le placement de la foliotation. Autorisé pour imprimés
et manuscrits.
plc-right-bottom
Right Bottom / Bas-droite
At the bottom right of the page. For print texts, the bottom is the forme work area.
For manuscripts, use your judgement about what constitutes the bottom of the page.
Note that catchwords are assumed to be right-bottom, so you do not need to add a place
attribute and value. Allowed in print and manuscript texts.
Dans la marge inférieure à droite de la page. Pour les textes imprimés, désigne le
blanc de pied. Pour les manuscrits, à l’appréciation de l’éditeur. Notez que les réclames
sont en bas à droite par défaut, il n’est pas pas nécessaire d’ajouter un attribut
et une valeur d’emplacement. Autorisé pour les imprimés et les manuscrits.
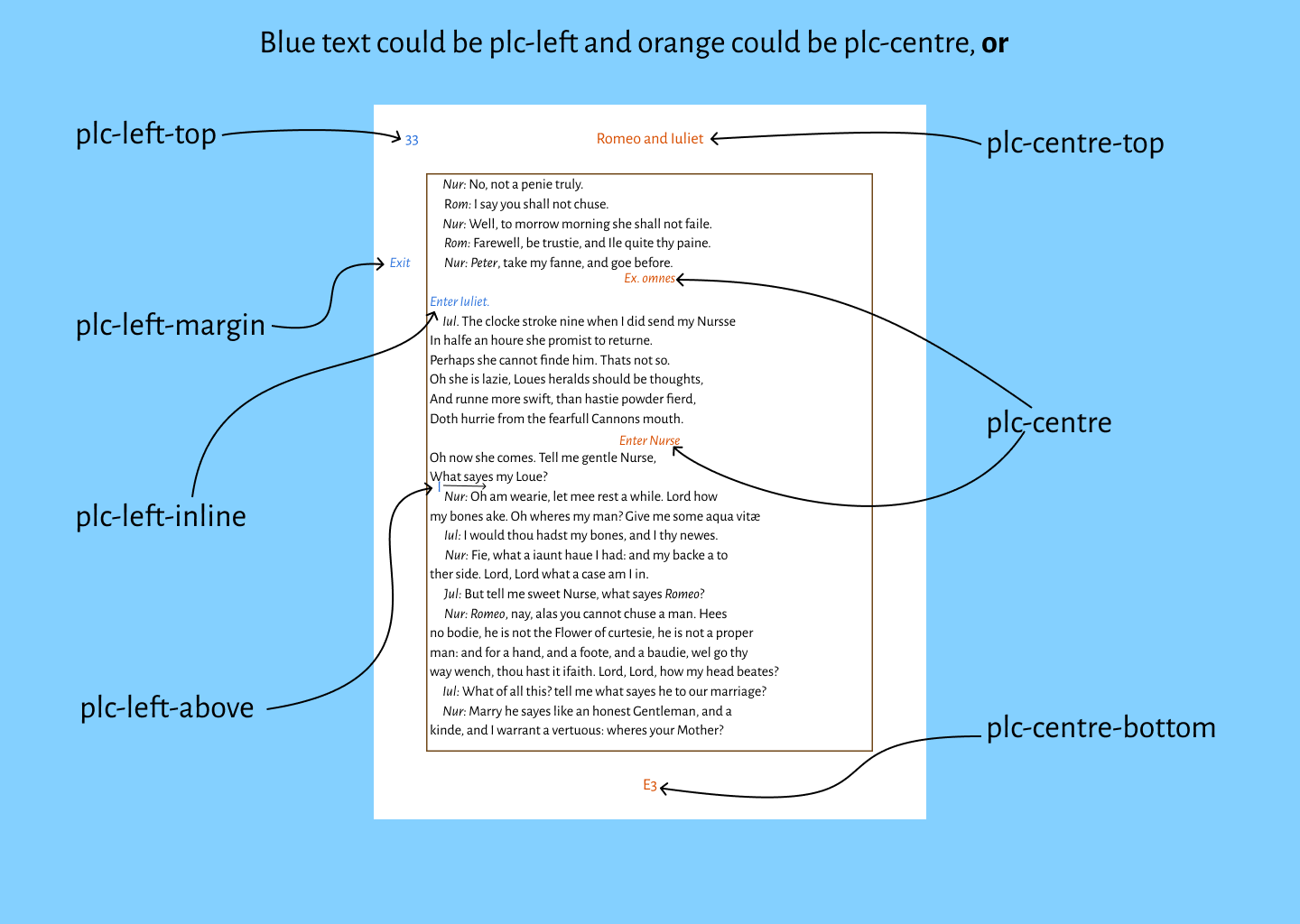
plc-left
Left / Gauche
A generic place value for anything to the left of the text or a figure, or on the
left side of an otherwise empty line (in print) or space (in manuscript). Use this
value for transcriptions of print or manuscript texts if your anthology is not using
the more granular values of left-margin, left-inline, left-top, and left-bottom. Allowed
in print and manuscript texts.
Emplacement par défaut à la gauche du texte ou d’une image, ou à la gauche de la ligne
vide d’un livre imprimé / de l’espace vide d’un manuscrit. À utiliser pour la transcription
d’un texte imprimé ou manuscrit si l’anthologie n’utilise pas les valeurs plus spécifiques
de marge-gauche, intégré-gauche, adjacent-gauche, haut-gauche, bas-gauche. Autorisé
pour imprimés et manuscrits.
plc-left-margin
Left Margin / Marge gauche
In the left margin. For print texts, the left margin is a formal area to the left
of the text block. For manuscripts, use your judgement about what constitutes the
marginal area. Allowed in print and manuscript texts.
Dans la marge gauche. Pour les imprimés, la marge gauche définit la zone à la gauche
du bloc de texte. Ce qui constitue la marge dans le cas des manuscrits est à l’appréciation
de l’éditeur. Autorisé pour imprimés et manuscrits.
plc-left-inline
Left Inline (Print) / Intégré gauche (imprimé)
Within a compositorial line of a printed text and aligned to the left margin. Allowed
only in print texts. Prohibited in manuscript texts.
Dans le corps du texte imprimé et aligné sur la marge gauche. Proscrit dans les manuscrits.
plc-left-top
Left Top / Haut gauche
At the top left of the page. For print texts, the top is the forme work area. For
manuscripts, use your judgement about what constitutes the top of the page. For print
folio collections, use this value to indicate placement of page numbers. For manuscripts,
use this value to indicate placement of foliation numbers. Allowed in print and manuscript
texts.
En haut à gauche de la page. Pour les textes imprimés, il s’agit du blanc de tête.
Pour les manuscrits, à l’appréciation de l’éditeur. Pour les imprimés, utilisez cette
valeur pour indiquer l’emplacement de la pagination; our les manuscrits, celui de
la foliotation. Autorisé pour imprimés et manuscrits.
plc-left-bottom
Left Bottom / Bas gauche
At the bottom left of the page. For print texts, the bottom is the forme work area.
For manuscripts, use your judgement about what constitutes the bottom of the page.
Allowed in print and manuscript texts.
Dans la marge inférieure gauche de la page. Pour les textes imprimés, désigne le blanc
de pied. Pour les manuscrits, à l’appréciation de l’éditeur. Autorisé pour imprimés
et manuscrits.
plc-centre
Centre / Centre
A generic place value for anything centered roughly horizontally in a line or area
on the page. Use this value in any print text (regardless of anthology policy) if
you want to indicate that a compositorial line is centered (e.g., Finis). Use this
value for transcriptions of print or manuscript texts if your anthology is not using
the more granular values of centre-top and centre-bottom. Allowed in print and manuscript
texts.
Valeur générique pour l’emplacement de tout élément centré horizontalement sur une
ligne ou zone de la page. Utiliser cette valeur dans tout texte imprimé (quelle que
soit la politique éditoriale de l’anthologie) si vous souhaitez indiquer qu’une ligne
de la composition est centrée (par ex: Finis). A utiliser pour les transcriptions
d’imprimés ou manuscrits si l’anthologie n’utilise pas les valeurs spécifiques de
haut-centre et bas- centre. Autorisé pour imprimés et manuscrits.
plc-centre-top
Centre Top / Centre haut
At the top centre of the page. For print texts, the top is the forme work area. For
manuscripts, use your judgement about what constitutes the top of the page. Note that
running titles are assumed to be centre-top, so you do not need to add a place attribute
and value. Allowed in print and manuscript texts.
En haut de la page et centré. Pour les imprimés, il s’agit du blanc de tête. Pour
les manuscrits, à l’appréciation de l’éditeur. Notez que les titres courants sont
centre-haut par défaut, il n’est pas nécessaire de leur assigner un attribut ou une
valeur d’emplacement. Autorisé pour imprimés et manuscrits.
plc-centre-bottom
Centre Bottom / Centre bas
At the bottom centre of the page. For print texts, the bottom is the forme work area.
For manuscripts, use your judgement about what constitutes the bottom of the page.
Note that signature numbers are assumed to be centre-bottom, so you do not need to
add a place attribute and value. Allowed in print and manuscript texts.
Dans la marge inférieure de la page. Pour les textes imprimés, désigne le blanc de
pied. Pour les manuscrits, à l’appréciation de l’éditeur. Notez que les signatures
sont centre-bas par défaut, il n’est pas nécessaire d’ajouter un attribut et une valeur
d’emplacement. Autorisé pour les imprimés et les manuscrits.
plc-bottom
Bottom / Bas
A generic place value for anything at the bottom of the page. For print texts, the
bottom is the forme work area. For manuscripts, use your judgement about what constitutes
the bottom of the page. Use this value for transcriptions of print or manuscript texts
if your anthology is not using the more granular values of centre-bottom, left-bottom,
and right-bottom. Allowed in print and manuscript texts.
Valeur générique pour désigner l’emplacement de tout élément en bas de page. Pour
les imprimés, le bas de la page désigne le blanc de pied. Pour les manuscrits, c’est
à l’appréciation de l’éditeur. A utiliser pour les transcriptions d’imprimés ou manuscrits,
si l’anthologie n’utilise pas les valeurs spécifiques de centre-bas, bas-gauche et
bas-droite. Autorisé pour imprimés et manuscrits.
plc-top
Top / Haut
A generic place value for anything at the top of the page. For print texts, the top
is the forme work area. For manuscripts, use your judgement about what constitutes
the top of the page. Use this value for transcriptions of print or manuscript texts
if your anthology is not using the more granular values of centre-top, left-top, and
right-top. Allowed in print and manuscript texts.
Valeur générique pour tout élément situé en haut de la page. Pour les textes imprimés,
le haut de la page désigne le blanc de tête. Pour les manuscrits, c’est à l’appréciation
de l’éditeur. A utiliser pour les transcriptions d’imprimés ou manuscrits si l’anthologie
n’utilise pas les valeurs spécifiques de centre-haut, haut-gauche et haut-droite.
Autorisé pour imprimés et manuscrits.
plc-inline
Inline
A generic place value for anything on its own compositorial line but not aligned right,
left, or centre.
plc-right-above
Right Above (manuscript) / Droite dessus
Above and to the right of the text, floating (possibly added at a later stage). Allowed
only in manuscript texts. Prohibited in print texts.
Au-dessus à droite du texte, flottant (possiblement un ajout ultérieur). Autorisé
seulement dans les manuscrits, proscrit dans les textes imprimés.
plc-right-below
Right Below (manuscript) / Droite dessous
Below and to the right of the text, floating (probably added at a later stage). Allowed
only in manuscript texts. Prohibited in print texts.
Au-dessous et à droite du texte, flottant (possiblement un ajout ultérieur). Autorisé
seulement dans les manuscrits, proscrit dans les textes imprimés.
plc-left-above
Left Above (manuscript) / Gauche dessus
Above and to the left of the text, floating (possibly added at a later stage). Allowed
only in manuscript texts. Prohibited in print texts.
Au-dessus à gauche du texte, flottant (possiblement un ajout ultérieur). Autorisé
seulement dans les manuscrits, proscrit dans les textes imprimés.
plc-left-below
Left Below (manuscript) / Gauche dessous
Below and to the left of the text, floating (probably added at a later stage). Allowed
only in manuscript texts. Prohibited in print texts.
Au-dessous et à gauche du texte, flottant (possiblement un ajout ultérieur). Autorisé
seulement dans les manuscrits, proscrit dans les textes imprimés.
plc-centre-above
Centre Above (manuscript) / Centre dessus
Centered above the text, floating (probably added at a later stage). Allowed only
in manuscript texts. Prohibited in print texts.
Centré et au-dessus du texte, flottant (possiblement un ajout ultérieur). Autorisé
seulement dans les manuscrits, proscrit dans les textes imprimés.
plc-centre-below
Centre Below (manuscript) / Centre dessous
Centered below the text, floating (probably added at a later stage). Allowed only
in manuscript texts. Prohibited in print texts.
Centré en dessous du texte, flottant (possiblement un ajout ultérieur). Autorisé seulement
dans les manuscrits, proscrit dans les textes imprimés.
plc-above
Above (manuscript) / Dessus
A generic place value for anything above the text and floating (probably added at
a later stage). Allowed only in manuscript texts. Prohibited in print texts.
Valeur générique pour tout élément placé au-dessus d’un élément textuel, flottant
(possiblement un ajout ultérieur). Autorisé seulement dans les manuscrits, proscrit
dans les textes imprimés.
plc-below
Below (manuscript) / Dessous
A generic place value for anything below the text and floating (probably added at
a later stage). Allowed only in manuscript texts. Prohibited in print texts.
Valeur générique pour tout élément placé sous un élément textuel, flottant (possiblement
un ajout ultérieur). Autorisé seulement dans les manuscrits, proscrit dans les textes
imprimés.
plc-opposite
Opposite (manuscript) / En face
A generic place value for anything on the opposite [i.e., facing] page (possibly added
at a later stage). Allowed only in manuscript texts. Prohibited in print texts.
Valeur générique pour tout élément placé sur la page opposée (en face) (possiblement
un ajout ultérieur). Autorisé seulement dans les manuscrits, proscrit dans les textes
imprimés.
plc-overleaf
Overleaf (manuscript) / page d’après
A generic place value for anything on the other side of the leaf (possibly added at
a later stage). Allowed only in manuscript texts. Prohibited in print texts.
Valeur générique pour tout élément placé de l’autre côté de la feuille (possiblement
un ajout ultérieur). Autorisé seulement dans les manuscrits, proscrit dans les textes
imprimés.
plc-inspace
Inspace (manuscript) / Intercalé
In a predefined space, [i.e., left by an earlier scribe]. Allowed only in manuscript
texts. Prohibited in print texts.
Intercalé dans un espace prédéfini (laissé par un scripteur précédent, par exemple).
Autorisé seulement dans les manuscrits, proscrit dans les textes imprimés.
plc-overwritten
Overwritten (manuscript) / Réécrit
A generic place value for any additional material written over deleted material. Allowed
only in manuscript texts. Prohibited in print texts.
Valeur générique pour tout élément ajouté par-dessus un ou plusieurs éléments supprimés.
Autorisé seulement dans les manuscrits, proscrit dans les textes imprimés.
plc-CHECK
THIS VALUE NEEDS TO BE CHECKED AND REASSIGNED.
Used where there is no direct conversion from old values, so human intervention is
required.
Utilisé lorsqu’il n’y a pas de conversion directe des anciennes valeurs possible,
ce qui nécessite une intervention humaine.
Understanding LEMDO’s Placement Value
Choosing a placement value requires understanding what each part of the value means
and how LEMDO refers to different parts of the page. The following images illustrate
what our terminology means.
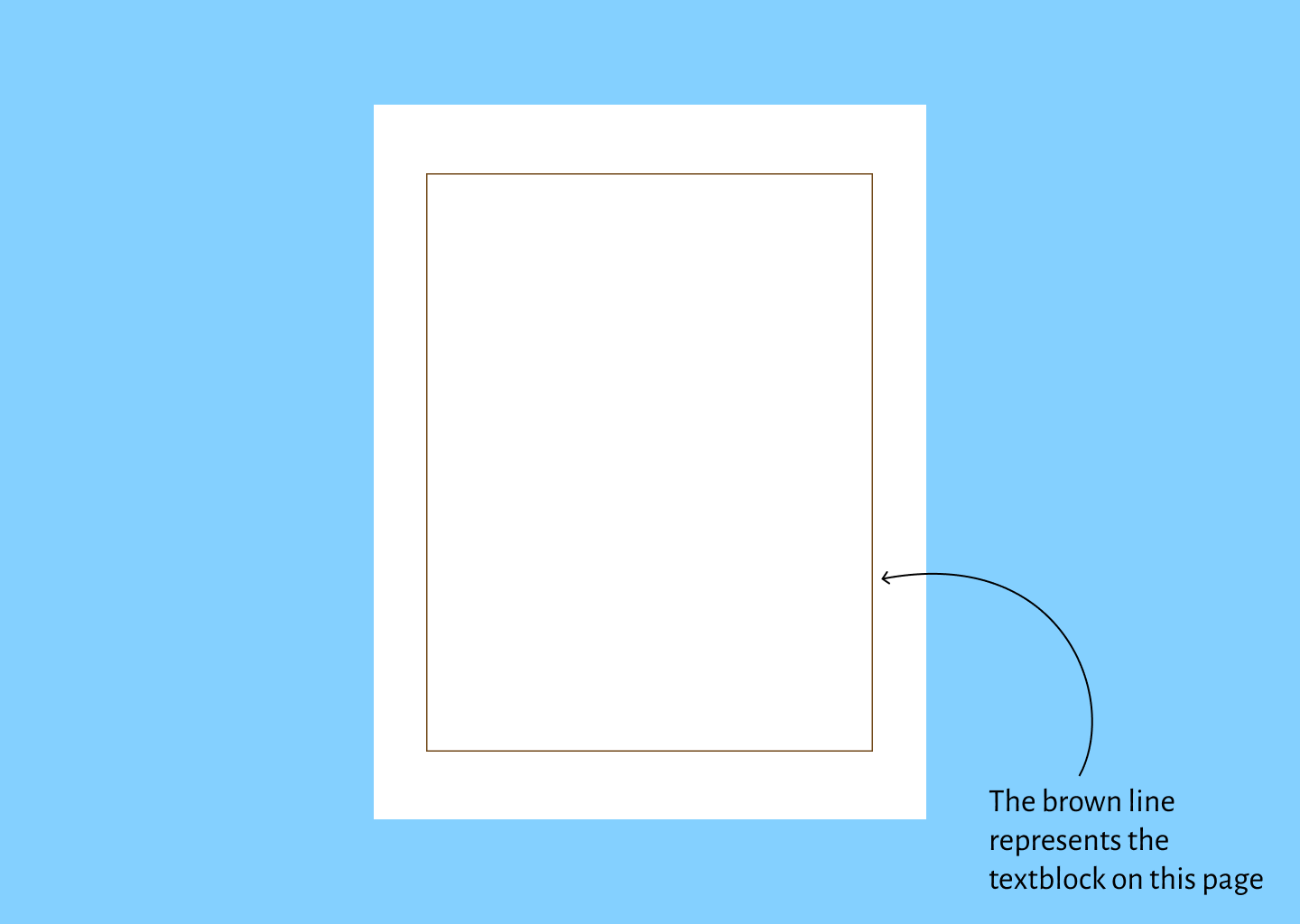
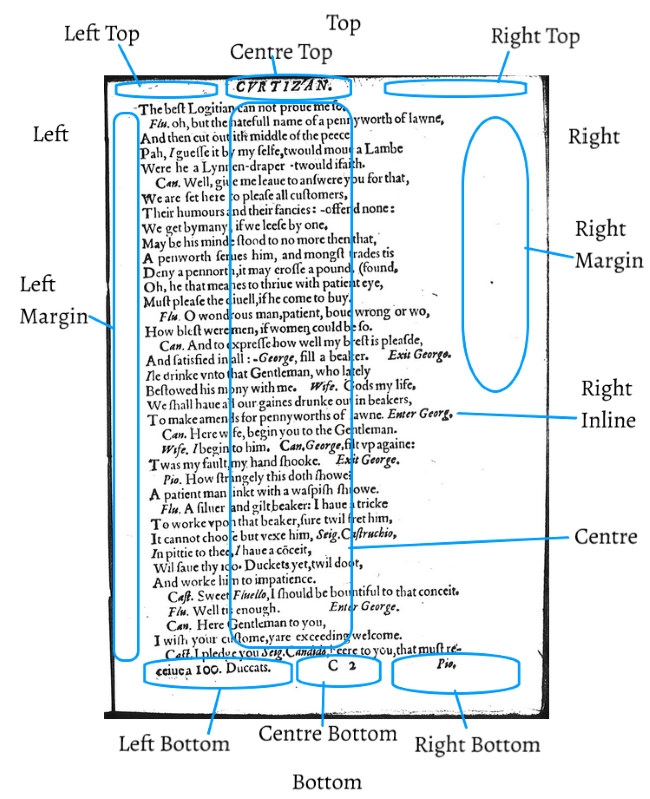
In this image of a page, the brown line shows the boundary of what we consider the
textblock:
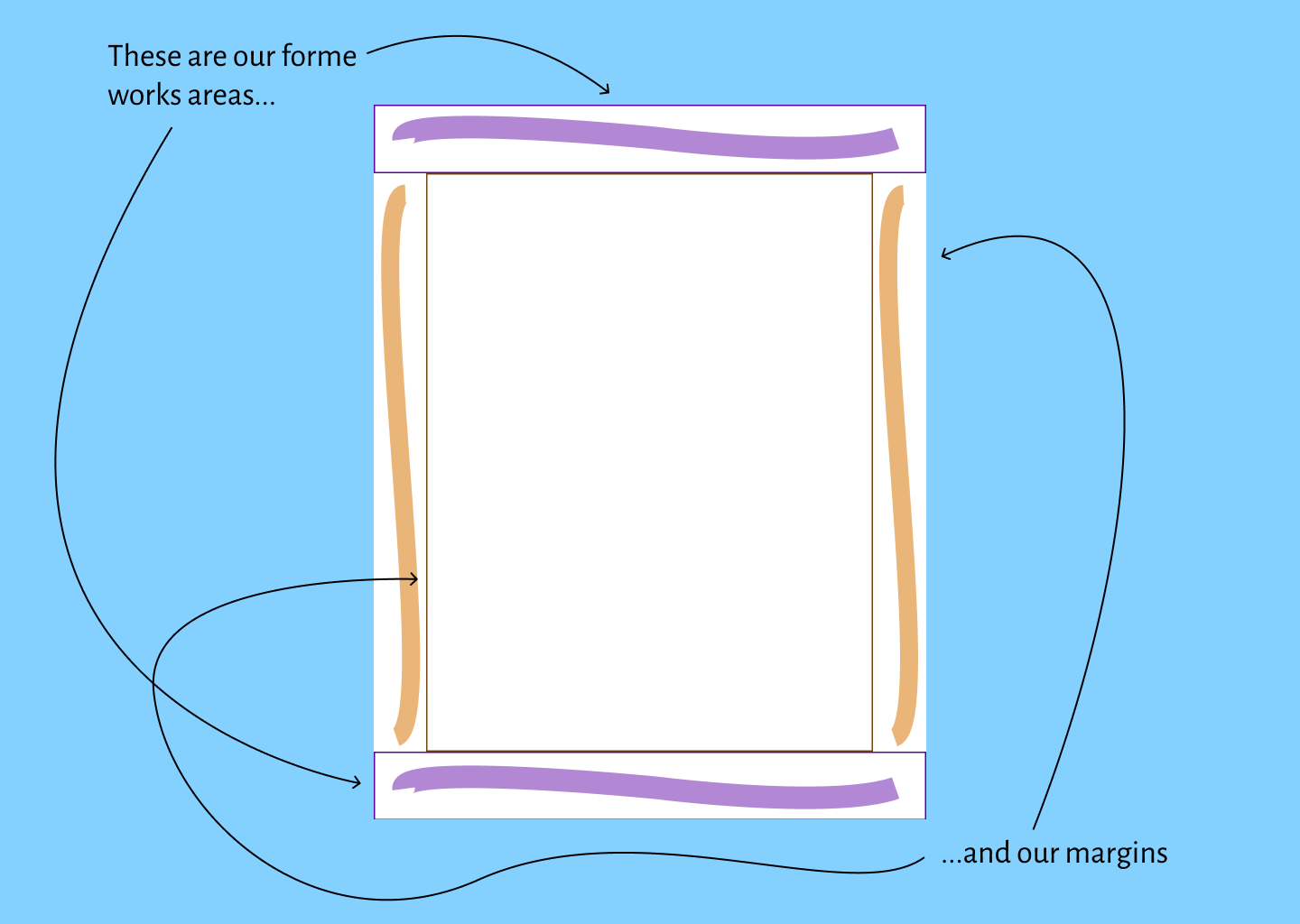
To the top and bottom of the textblock are the forme works areas (highlighted in purple).
To either side of the textblock are the margins (highlighted in orange).
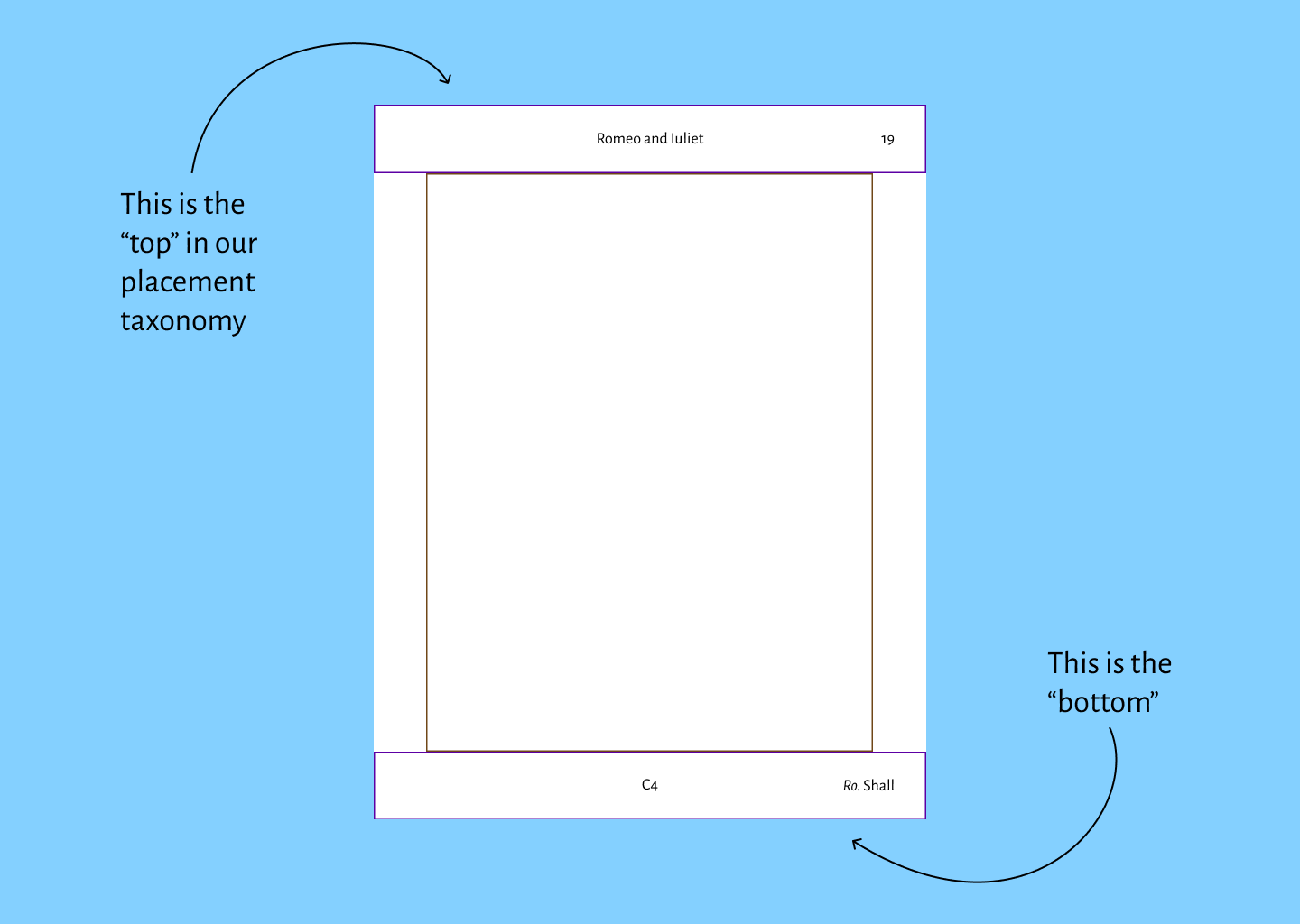
In our placement taxonomy, we consider things in the top forme works area to be “top”
while things in the bottom forme works area are described with values that have “bottom”
in them.
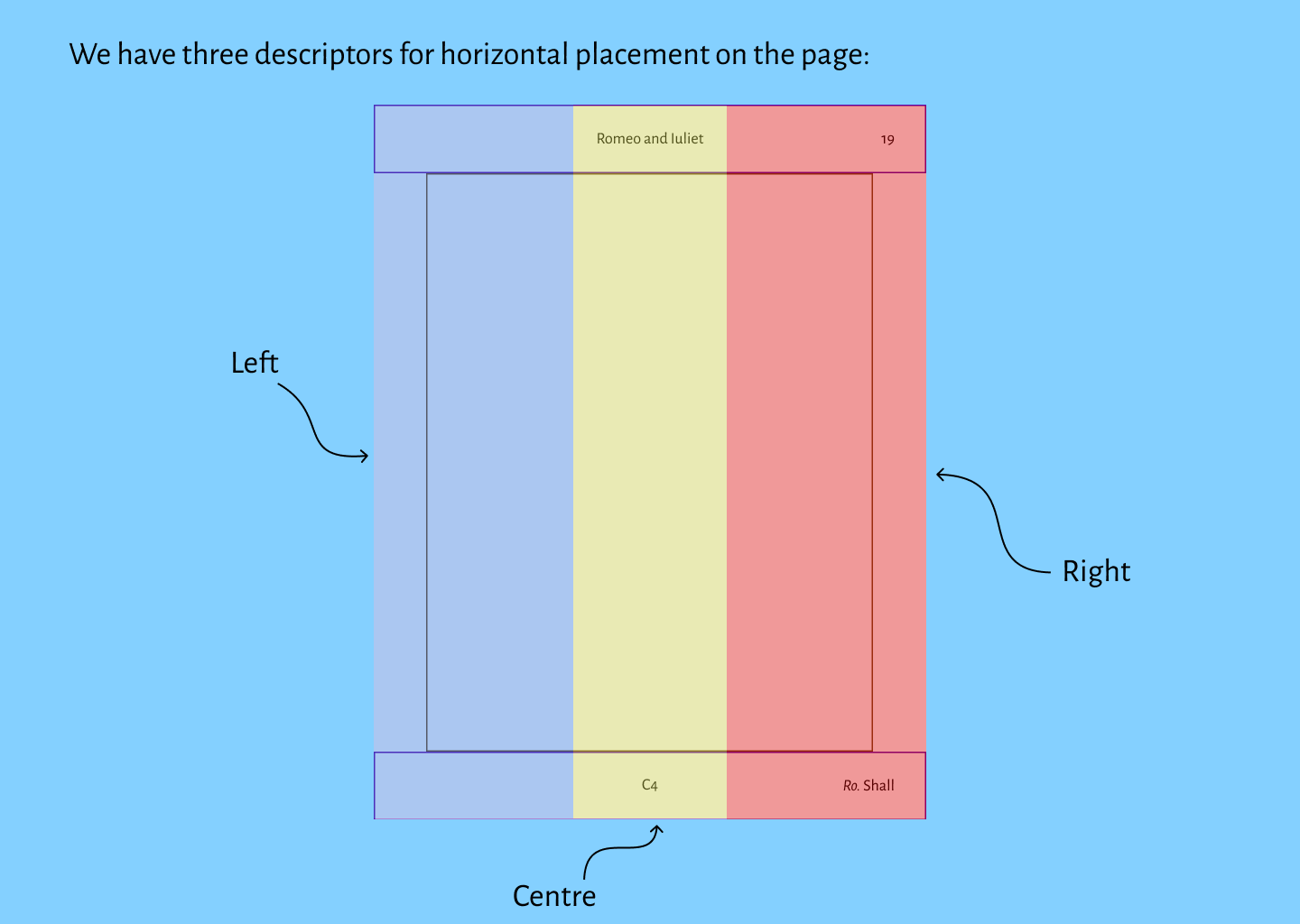
We determine horizontal descriptors (left, right, centre) based on zones as shown
in the following image:
Anything in the left zone (highlighted blue) should have “left” in its
@place value, anything in the centre zone (highlighted yellow) should have “centre” in its
@place value, and anything in the right zone (highlighted red) should have “right” in its
@place value.
While we do allow generic values based on zone only (e.g., plc-right), in most cases we can provide more specific values without extra work. The specific
values for text in the right zone can be tagged with values as shown in the following
image:
There are less values for text in the left and centre zones because there is less
variation in the left and centre areas of early modern pages. You can, however, tag
values as shown in this image:
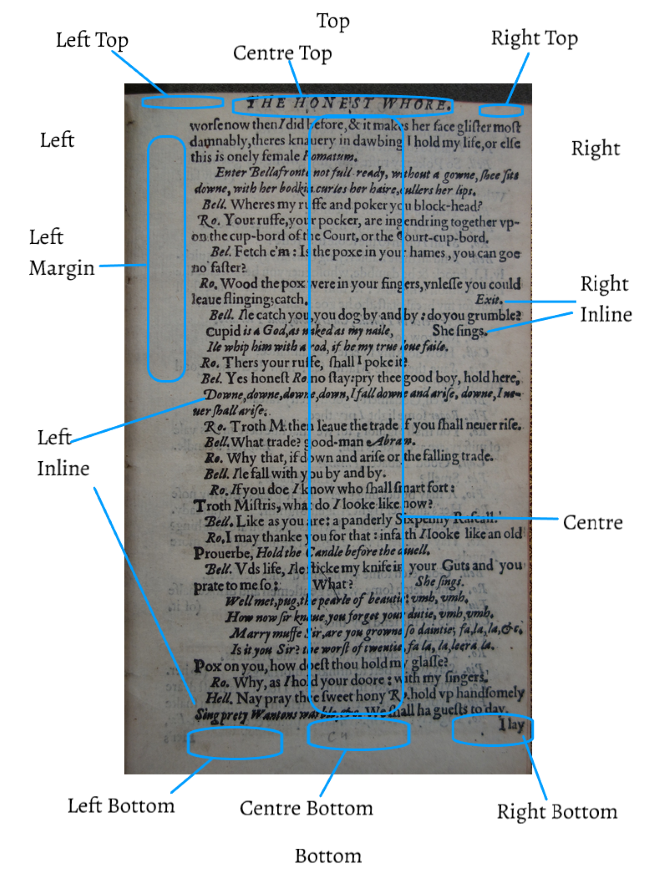
Examples
The following images are annotated semi-diplomatic print pages to serve as examples
of the above placement values.
An example page for print place values, including Right Adjacent, from Q2 Hamlet.An example page for print place values, including Left Bottom, from Q2 The Honest Whore, Part 1.An example page for print place values from Q1 The Honest Whore, Part 1.
While LEMDO no longer encourages anthologies to tag glyphs and ligatures in their
semi-diplomatic transcriptions, older LEMDO editions tagged glyphs using the values
documented on this page. To learn about LEMDO’s current practices for encoding glyphs,
see Encode Glyphs and Ligatures in Semi-Diplomatic Transcriptions.
Typographical Glyph Values
@xml:id
Glyph name
Mappings
Note
g_UNKNOWN
Unknown
standard: �
unicode: U+FFFD
This indicates something that needs investigation by an editor, and a better encoding
solution. It is a temporary option.
g_caret
Caret
modern: ^
standard: ^
unicode: U+2038
g_doubleHyphen
Double Oblique Hyphen
modern: -
standard: ⸗
unicode: U+2E17
g_amacron
Latin Small Letter a with Macron
modern: a[nm]
standard: ā
iml: {_a}
unicode: U+0101
The expansion of this glyph depends on its context; in most cases it involves the
addition of a nasal, but each case must be handled manually. See also Latin Small
Letter “a” with Tilde.
g_emacron
Latin Small Letter e with Macron
modern: e[nm]
standard: ē
iml: {_e}
unicode: U+0113
The expansion of this glyph depends on its context; in most cases it involves the
addition of a nasal, but each case must be handled manually. See also Latin Small
Letter “e” with Tilde.
g_imacron
Latin Small Letter i with Macron
modern: i[nm]
standard: ī
iml: {_i}
unicode: U+012B
The expansion of this glyph depends on its context; in most cases it involves the
addition of a nasal, but each case must be handled manually. See also Latin Small
Letter “i” with Tilde.
g_mmacron
Latin Small Letter m with Macron
modern: m[nm]
standard: m̄
iml:
The expansion of this glyph depends on its context; in most cases it involves the
addition of a nasal, but each case must be handled manually. See also Latin Small
Letter “o” with Tilde.
g_nmacron
Latin Small Letter n with Macron
modern: n[nm]
standard: n̄
iml:
The expansion of this glyph depends on its context; in most cases it involves the
addition of a nasal, but each case must be handled manually. See also Latin Small
Letter “o” with Tilde.
g_omacron
Latin Small Letter o with Macron
modern: o[nm]
standard: ō
iml: {_o}
unicode: U+014D
The expansion of this glyph depends on its context; in most cases it involves the
addition of a nasal, but each case must be handled manually. See also Latin Small
Letter “o” with Tilde.
g_umacron
Latin Small Letter u with Macron
modern: u[nm]
standard: ū
iml: {_u}
unicode: U+016B
The expansion of this glyph depends on its context; in most cases it involves the
addition of a nasal, but each case must be handled manually. See also Latin Small
Letter “u” with Tilde.
g_wmacron
Latin Small Letter w with Macron
modern: w[nm]
standard: w̄
iml: {_w}
unicode: w U+0304
g_ymacron
Latin Small Letter y with Macron
modern: y[nm]
standard: ȳ
iml: {_y}
unicode: U+0233
The expansion of this glyph depends on its context; in most cases it involves the
addition of a nasal, but each case must be handled manually.
g_e
Combining Latin Small Letter e
modern: e
standard: e
unicode: U+0364
Usually in combination with y, and the ye combination will need to be tagged with
choice, abbr, and expan to expand the y into th.
g_u
Combining Latin Small Letter u
modern: u
standard: u
unicode: U+0367
Usually in combination with y, and the yu combination will need to be tagged with
choice, abbr, and expan to expand the y into th. The editor will need to determine
if the word should be expanded to thou or you.
g_t
Combining Latin Small Letter t
modern: t
standard: t
unicode: U+036D
Usually in combination with y, and the yt combination will need to be tagged with
choice, abbr, and expan to expand the y into th.
g_atilde
Latin Small Letter a with Tilde
modern: a[nm]
standard: ã
iml: {~a}
unicode: U+00E3
The expansion of this glyph depends on its context; in most cases it involves the
addition of a nasal, but each case must be handled manually. See also Latin Small
Letter a With Macron.
g_etilde
Latin Small Letter e with Tilde
modern: e[nm]
standard: ẽ
iml: {~e}
unicode: U+1EBD
The expansion of this glyph depends on its context; in most cases it involves the
addition of a nasal, but each case must be handled manually. See also Latin Small
Letter e With Macron.
g_itilde
Latin Small Letter i with Tilde
modern: i[nm]
standard: ĩ
iml: {~i}
unicode: U+0129
The expansion of this glyph depends on its context; in most cases it involves the
addition of a nasal, but each case must be handled manually. See also Latin Small
Letter i with Macron.
g_ocircumflex
Latin Small Letter o with Circumflex
modern: o
standard: ô
unicode: U+00D4
g_otilde
Latin Small Letter o with Tilde
modern: o[nm]
standard: õ
iml: {~o}
unicode: U+00F5
The expansion of this glyph depends on its context; in most cases it involves the
addition of a nasal, but each case must be handled manually. See also Latin Small
Letter o with Macron.
p_macron
Latin small letter p with macron
modern: p̄
standard: p̄
unicode: U+0070U+0304
g_utilde
Latin Small Letter u with Tilde
modern: u[nm]
standard: ũ
iml: {~u}
unicode: U+0169
The expansion of this glyph depends on its context; in most cases it involves the
addition of a nasal, but each case must be handled manually. See also Latin Small
Letter u with Macron.
g_ntilde
Latin Small Letter n with Tilde
modern: ñ
standard: ñ
iml: {~n}
unicode: U+00F1
g_udiaeresis
Latin Small Letter u with Diaeresis
modern: u
standard: ü
unicode: U+00FC
g_longS
Latin Small Letter Long s
modern: s
standard: ſ
iml: {s}
unicode: U+017F
g_thorn
Latin Capital Letter Thorn
modern: th
standard: þ
iml: {th}
unicode: U+00FE
g_wynn
Latin Letter Wynn
modern: w
standard: ƿ
unicode: U+01BF
g_eth
Latin Small Letter Eth
modern: th
standard: ð
unicode: U+00F0
g_vv
Lowercase Double v for w
modern: w
standard: w
typeset: vv
iml: {vv}
iml: {w}
g_VV
Uppercase Double V for W
modern: W
standard: W
typeset: VV
iml: {VV}
iml: {W}
g_rotunda
Latin Small Letter r Rotunda
modern: r
standard: ꝛ
iml: {r}
unicode: U+A75A
g_zeroWidthSpace
Zero Width Space
modern:
standard:
iml: {#}
unicode: U+200B
g_cutp
Latin Small Letter p with Stroke Through Descender
modern: ꝑ
standard: ꝑ
unicode: U+A751
g_cutP
Latin Capital Letter P with Stroke Through Descender
modern: Ꝑ
standard: Ꝑ
unicode: U+A750
g_que
Latin Small Letter et, meaning que
modern: ꝫ
standard: ꝫ
unicode: U+A76B
g_con
Latin Small Letter Con
modern: con
standard: ꝯ
unicode: U+A76F
g_us
Modifier Small Letter us Superscripted
modern: us
standard: ꝰ
unicode: U+A770
g_us_Eng
Modifier Letter us in English MS Not Superscript
modern: us
standard: Ꝯ
unicode: U+A76E
g_ye
Modifier y Small e Above
modern: ye
standard: ye
g_yt
Modifier y Small t Above
modern: yt
standard: yt
Typographical Ligatures Taxonomy
While LEMDO no longer encourages anthologies to tag glyphs and ligatures in their
semi-diplomatic transcriptions, some semi-diplomatic files (mostly inherited from
other projects) tagged ligatures using the values documented on this page. To learn
about LEMDO’s current practices for encoding ligatures, see Encode Glyphs and Ligatures in Semi-Diplomatic Transcriptions.
Typographical Ligature Values
@xml:id
Glyph name
Mappings
lig_AE
Latin Capital Letter/Ligature AE
modern: ae
standard: AE
precomposed: Æ
iml: {AE}
unicode: U+00C6
lig_ae
Latin Small Letter/Ligature ae
modern: ae
standard: ae
precomposed: æ
iml: {ae}
unicode: U+00E6
lig_as
Latin Small Ligature as
modern: as
standard: as
iml: {as}
lig_ct
Latin Small Ligature ct
modern: ct
standard: ct
iml: {ct}
lig_ee
Latin Small Ligature ee
modern: ee
standard: EE
iml: {ee}
lig_es
Latin Small Ligature es
modern: es
standard: es
lig_ess
Latin Small Ligature e Long s Short s
modern: ess
standard: eſs
iml: {e{s}s}
lig_fa
Latin Small Ligature fa
modern: fa
standard: fa
iml: {fa}
lig_fe
Latin Small Ligature fe
modern: fe
standard: fe
iml: {f}
lig_ff
Latin Small Ligature ff
modern: ff
standard: ff
precomposed: ff
iml: {ff}
unicode: U+FB00
lig_ffa
Latin Small Ligature ffa
modern: ffa
iml: {ffa}
lig_ffe
Latin Small Ligature ffe
modern: ffe
iml: {ffe}
lig_ffi
Latin Small Ligature ffi
modern: ffi
standard: ffi
precomposed: ffi
iml: {ffi}
unicode: U+FB03
lig_ffl
Latin Small Ligature ffl
modern: ffl
standard: ffl
precomposed: ffl
iml: {ffl}
unicode: U+FB04
lig_ffr
Latin Small Ligature ffr
modern: ffr
iml: {ffr}
lig_fi
Latin Small Ligature fi
modern: fi
standard: fi
precomposed: fi
iml: {fi}
unicode: U+FB01
lig_fl
Latin Small Ligature fl
modern: fl
standard: fl
precomposed: fl
iml: {fl}
unicode: U+FB02
lig_fo
Latin Small Ligature fo
modern: fo
standard: fo
iml: {fo}
lig_fr
Latin Small Ligature fr
modern: fr
standard: fr
iml: {fr}
lig_ft
Latin Small Ligature ft
modern: ft
standard: ft
iml: {ft}
lig_fu
Latin Small Ligature fu
modern: fu
iml: {ffu}
lig_IJ
Latin Capital Ligature IJ
modern: IJ
standard: IJ
precomposed: IJ
iml: {IJ}
unicode: U+0132
lig_ij
Latin Small Ligature ij
modern: ij
standard: ij
precomposed: ij
iml: {ij}
unicode: U+0133
lig_is
Latin Small Ligature is
modern: is
standard: is
iml: {is}
lig_ll
Latin Small Ligature ll
modern: ll
standard: ll
iml: {ll}
lig_oe
Latin Small Letter/Ligature oe
modern: oe
standard: OE
precomposed: œ
iml: {oe}
unicode: U+1053
lig_oo
Latin Small Letter/Ligature oo
modern: oo
standard: oo
iml: {oo}
lig_os
Latin Small Ligature os
modern: os
standard: os
iml: {os}
lig_Qu
Latin Ligature Capital Q Small u
modern: Qu
standard: Qu
lig_Que
Latin Ligature Capital Q Small u Small e
modern: Que
standard: Que
lig_Qui
Latin Ligature Capital Q Small u Small i
modern: Qui
standard: Qui
lig_longS_a
Latin Small Ligature Long s a
modern: sa
standard: ſa
iml: {{s}a}
lig_longS_b
Latin Small Ligature Long s b
modern: sb
standard: ſb
iml: {{s}b}
lig_longS_c
Latin Small Ligature Long s c
modern: sc
standard: sc
iml: {{s}c}
lig_longS_e
Latin Small Ligature Long s e
modern: se
standard: ſe
iml: {s{e}}
lig_longS_g
Latin Small Ligature Long s g
modern: sg
standard: ſg
iml: {{s}g}
lig_longS_h
Latin Small Ligature Long s h
modern: sh
standard: ſh
iml: {{s}h}
lig_longS_i
Latin Small Ligature Long s i
modern: si
standard: ſi
iml: {{s}i}
lig_sk
Latin Small Ligature sk
modern: sk
standard: sk
iml: {sk}
lig_sl
Latin Small Ligature sl
modern: sl
standard: sl
iml: {sl}
unicode: U+FB06
lig_longS_k
Latin Small Ligature Long s k
modern: sk
standard: ſk
iml: {sk}
lig_longS_l
Latin Small Ligature Long s l
modern: sl
standard: ſl
iml: {{s}l}
lig_longS_m
Latin Small Ligature Long s m
modern: sm
standard: ſm
iml: {{s}m}
lig_longS_n
Latin Small Ligature Long s n
modern: sn
standard: ſn
iml: {{s}n}
lig_longS_o
Latin Small Ligature Long s o
modern: so
standard: ſo
iml: {{s}o}
lig_sp
Latin Small Ligature sp
modern: sp
standard: sp
iml: {sp}
lig_longS_p
Latin Small Ligature Long s p
modern: sp
standard: ſp
iml: {{s}p}
lig_longS_q
Latin Small Ligature Long s q
modern: sq
standard: ſq
iml: {{s}q}
lig_longS_longS
Latin Small Ligature Long s Long s
modern: ss
standard: ſſ
iml: {{s}{s}}
lig_longS_longS_a
Latin Small Ligature Long s Long s a
modern: ssa
standard: ſſa
iml: {{s}{s}a}
lig_longS_longS_e
Latin Small Ligature Long s Long s e
modern: sse
standard: ſſe
iml: {{s}{s}e}
lig_longS_longS_i
Latin Small Ligature Long s Long s i
modern: ssi
standard: ſſi
iml: {{s}{s}i}
lig_longS_longS_l
Latin Small Ligature Long s Long s l
modern: ssl
standard: ſſl
iml: {{s}{s}l}
lig_longS_longS_o
Latin Small Ligature Long s Long s o
modern: sso
standard: ſſo
iml: {{s}{s}o}
lig_st
Latin Small Ligature st
modern: st
standard: st
precomposed: st
iml: {st}
unicode: U+FB06
lig_longS_t
Latin Small Ligature Long s t
modern: st
standard: ſt
precomposed: ſt
iml: {{s}t}
unicode: U+FB05
lig_ss
Latin Small Ligature Long s Short s
modern: ss
standard: ſs
iml: {{s}s}
lig_longS_u
Latin Small Ligature Long s u
modern: su
standard: ſu
iml: {{s}u}
lig_longS_w
Latin Small Ligature Long s w
modern: sw
standard: ſw
iml: {{s}w}
lig_sz
Latin Small Letter Sharp s (Eszett)
modern: ss
standard: ss
iml: {ß}
unicode: U+00DF
lig_us
Latin Small Ligature us
modern: us
standard: us
iml: {us}
lig_Wt
Latin Ligature Wt
modern: with
standard: Wt
iml: {Wt}
lig_wt
Latin Ligature wt
modern: with
standard: wt
iml: {wt}
DRE Play IDs
Every play in the LEMDO repository has an abbreviated ID. These IDs are used across
the site in a variety of places:
As the title of a edition directory (e.g., /Ham).
In the xml:id of a file within a play’s edition (e.g., emdHam_GenIntro.xml)
In citations (e.g., Ham 10.70–72)
LEMDO normally uses the IDs created for the Bibliography of Editions of Early English Drama (BEEED), except for a few legacy editions. IDs for mayoral pageant books match those
of the Map of Early Modern London (e.g., The Triumphs of Truth is TRIU1).
Title
ID
Author
Year
The Castle of Perseverance
CPer
Anonymous
1400
The Pride of Life
PLif
Anonymous
1400
The Play of the Sacrament (The Croxton Play of the Sacrament)
PSac
Anonymous
1460
Occupation and Idleness
Ocpn
Anonymous
1460
Mankind
Man
Anonymous
1465
Wisdom, Who is Christ
Wisd
Anonymous
1465
Robin Hood and the Sheriff (Robin Hood and the Knight)
RHSh
Anonymous
1475
The Killing of the Children
DKC
Anonymous
1485
The Prodigal Son (Pater, Filius et Uxor)
PrdS
Anonymous
1490
Youth
Yth
Anonymous
1490
The Nature of the Four Elements
N4E
Anonymous
1490
1 and 2 Nature (Nature)
Nat
Henry Medwall
1496
Fulgens and Lucres
FLuc
Henry Medwall
1497
Hick Scorner
Hick
Anonymous
1514
Mundus et Infans (The World and the Child)
Mund
Anonymous
1515
The Summoning of Everyman
EMan
Anonymous
1519
John the Evangelist
JnEv
Anonymous
1520
The Conversion of St Paul (The Digby Conversion of St Paul)
ConP
Anonymous
1520
Mary Magdalen (The Digby Mary Magdalen)
DMM
Anonymous
1520
John John the Husband
JnJn
John Heywood
1520
The Pardoner and the Friar
PaFr
John Heywood
1520
Magnificence
Magn
John Skelton
1520
Andria (The Woman from Andros)
Ter
Terence; Anonymous (trans.)
1520
The Four Ps (The Four PP)
4PP
John Heywood
1525
1 Gentleness and Nobility (Gentleness and Nobility, Part One)
1GN
John Heywood
1527
2 Gentleness and Nobility (Gentleness and Nobility, Part Two)
2GN
John Heywood
1527
Calisto and Melebea
CalM
John Rastell
1527
Godly Queen Hester (Godly Queen Esther)
QGH
Anonymous
1529
The Play of Love
PLov
John Heywood
1529
The Play of the Weather
Wthr
John Heywood
1533
Good Order (Old Christmas)
GOrd
John Skelton?
1533
A Dialogue between Julius II, Genius, and St Peter
JGSP
Desiderius Erasmus; Anonymous (trans.)
1534
A Disobedience, Temperancend Humility
DTH
Anonymous
1535
Funus (The Funeral)
Fns
Desiderius Erasmus; Anonymous (trans.)
1535
A Pilgrimage of Pure Devotion
PPDv
Desiderius Erasmus; Anonymous (trans.)
1536
Thersites (Thersytes)
Thrs
Nicholas Udall?
1537
A Pretty Complaint of Peace
PCmP
Anonymous
1538
The Three Laws
3Law
John Bale
1538
God’s Promises (The Chief Promises of God)
GodP
John Bale
1538
John Baptist’s Preaching in the Wilderness
JBpP
John Bale
1538
The Temptation of Our Lord
TmpL
John Bale
1538
King John (King Johan)
KJhn
John Bale
1538
The Four Cardinal Virtues
4CV
Anonymous
1540
A Governor (Ecclesia)
Gvnr
Ravisius Textor; Robert Radcliffe (trans.)
1540
A Dialogue on Fortune (Poor Man and Fortune)
DFor
Ravisius Textor; Robert Radcliffe (trans.)
1540
A Dialogue on Death (Death and the Goer by the Way)
DDth
Ravisius Textor; Robert Radcliffe (trans.)
1540
Acolastus
Acol
Willem de Volder; John Palsgrave (trans.)
1540
A Dialogue on Wit (Witty and Witless)
DWit
John Heywood
1543
Wit and Science
WtSc
John Redford
1544
The Epicure
Epcr
Desiderius Erasmus; Philip Gerrard (trans.)
1545
The Parts of Man (The Estate of Christ’s Church)
PtMn
John Heywood
1547
A Dialogue between the Angel of the Lord and the Shepherds (Gabriel and the Shepherds)
DASh
Thomas Becon
1547
The Seven Deadly Sins
SDSn
Anonymous
1548
A Goodly Dialogue between Knowledge and Simplicity
DKSm
Anonymous
1548
A Goodly Disputation between a Christian Shoemaker and a Popish Parson
CSPP
Hans Sachs; Anthony Skoloker (trans.)
1548
John Bon and Mast’ Parson
JBMP
Luke Sheperd
1548
The Indictment against Mother Mass
IAMM
William Punt
1548
The Examination of the Mass
ExM
William Turner
1548
The Unjust Usurped Supremacy of the Bishop of Rome
UnUs
Bernardino Ochino; John Ponet (trans.)
1549
Polyphemus (The Gospeller)
Pphm
Desiderius Erasmus; Edmond Becke (trans.)
1549
Things and Names
ThNm
Desiderius Erasmus; Edmond Becke (trans.)
1549
Play of the Resurrection
PRes
Anonymous
1550
Nice Wanton
NWan
Anonymous
1550
Mary Magdalene (The Life and Repentance of Mary Magdalen)
LRMM
Lewis Wager
1550
The Disobedient Child
DisC
Thomas Ingelend
1550
Show of the Nine Worthies
SNW
Richard Kaye?
1551
Lusty Juventus
LusJ
Richard Wever?
1551
The Satire of the Three Estates
S3E
David Lindsay
1552
Ralph Roister Doister
RRD
Nicholas Udall
1552
Jacob and Esau
JacE
Nicholas Udall?
1553
Gammer Gurton’s Needle
GGN
William Stevenson
1553
Respublica
Resp
Anonymous
1554
Wealth and Health
WthH
Anonymous
1554
Jack Juggler
JJug
Anonymous
1555
Iphigenia
Iphg
Euripides; Jane Lumley (trans.)
1555
Impatient Poverty
ImpP
Anonymous
1556
A Merry Dialogue declaring the Properties of Shrewd Shrews and Honest Wives
SSHW
Desiderius Erasmus; Anonymous (trans.)
1557
A Dialogue on Idleness
Idle
John Fisher
1558
A Dialogue on Maidens
DMdn
John Fisher
1558
A Dialogue concerning Wisdom and Will
DWW
John Fisher
1558
Troas
Trs
Seneca; Jasper Heywood (trans.)
1558
Robin Hood and the Friar
RHFr
Anonymous
1560
Robin Hood and the Potter
RHPt
Anonymous
1560
Oedipus
Oedp
Seneca; Alexander Neville (trans.)
1560
Thyestes
Thys
Seneca; Jasper Heywood (trans.)
1560
Tom Tyler and His Wife
TTHW
Anonymous
1561
The Pedlar’s Prophecy
PedP
Anonymous
1561
Patient and Meek Grissel
PMGr
John Phillip
1561
Hercules furens
HFur
Seneca; Jasper Heywood (trans.)
1561
Gorboduc (Ferrex and Porrex)
Gorb
Thomas Newton; Thomas Sackville
1562
The Virtuous and Godly Susanna
Susa
Thomas Garter
1563
July and Julian
JJul
Anonymous
1564
Masque at Hinchinbrook
MHin
Anonymous
1564
A Dialogue between the Cap and the Head
DCpH
Pandolfo Collenuccio; Anonymous (trans.)
1564
Robin Conscience
RobC
Anonymous
1565
The Temptation of Man in Paradise
TMPa
Anonymous
1565
Albion Knight
AlbK
Anonymous
1565
Darius
Dar
Anonymous
1565
Damon and Pythias (Damon and Pithias)
DamP
Richard Edwards
1565
The Banquet of Dainties
BanD
Anonymous
1566
Inns (Diversoria)
Inns
E. H. (trans.); Desiderius Erasmus
1566
Supposes
Supp
Ludovico Ariosto; George Gascoigne (trans.)
1566
Jocasta
Joc
Ludovico Dolce; Francis Kinwelmersh (trans.); Christopher Yelverton (trans.); George
Gascoigne (trans.)
1566
Octavia
Oct
Pseudo-Seneca; Thomas Nuce (trans.)
1566
Appius and Virginia
App
R. B.; Anonymous
1566
Palamon and Arcite (The Knight’s Tale)
PArc
Richard Edwards
1566
Agamemnon
Agmn
Seneca; John Studley (trans.)
1566
Medea
Meda
Seneca; John Studley (trans.)
1566
Hercules Oetaeus
HOet
Seneca; John Studley (trans.)
1566
The Cruel Debtor
CDbt
William Wager
1566
A Conjuration
Conj
Desiderius Erasmus; Thomas Johnson (trans.)
1567
The Bugbears
BugB
John Jeffere?
1567
Horestes
Hor
John Pickering
1567
Hippolytus
Hipp
Seneca; John Studley (trans.)
1567
The Trial of Treasure
TTr
William Wager
1567
The Marriage of Wit and Science
MWSc
Anonymous
1568
Gismund of Salerne (Tancred and Gismund)
Gism
Christopher Hatton; Henry Noel; Roderick Stafford; Robert Wilmot
1568
The Young Man and the Evil Disposed Woman
YMEW
Desiderius Erasmus; Nicholas Leigh (trans.)
1568
A Modest Mean to Marriage (Pamphilus and Maria)
MMMa
Desiderius Erasmus; Nicholas Leigh (trans.)
1568
Free Will (Free-Will)
FrW
Francesco Negri de Bassano; Henry Cheke (trans.)
1568
Like Will to Like
LWL
Ulpian Fulwell
1568
Enough is as Good as a Feast
EGF
William Wager
1568
Cambyses (Cambises)
Cmb
Thomas Preston
1569
The Longer Thou Livest the More Fool Thou Art
LLiv
William Wager
1569
Common Conditions
ComC
Anonymous
1570
A Spanish Gentleman and an English Gentlewoman
SGEG
Anonymous
1570
Love Feigned and Unfeigned
LFU
Anonymous
1571
The Masque for Lord Montague
MLMn
George Gascoigne
1572
The Conflict of Conscience
CoC
Nathaniel Woodes
1572
New Custom
NewC
Anonymous
1573
The Marriage Between Wit and Wisdom
MBWW
Francis Merbury
1575
The Glass of Government
GGov
George Gascoigne
1575
A Interlude of Minds
IntM
Hendrik Niclaes; Christopher Vittels (trans.)
1575
Abraham’s Sacrifice
ASac
Theodore de Beze; Arthur Golding (trans.)
1575
The Tide Tarrieth No Man
TTNM
George Wapull
1576
A Dialogue between Wisdom and Folly
DWF
John Kay
1576
Misogonus
Miso
Anthony Rudd?; Laurence Johnson?
1577
1 Promos and Cassandra (Promos and Cassandra, Part One)
1PC
George Whetstone
1577
2 Promos and Cassandra (Promos and Cassandra, Part Two)
2PC
George Whetstone
1577
A Dialogue between Two Shepherds
DShp
Philip Sidney
1577
All for Money
AFM
Thomas Lupton
1577
Clyomon and Clamydes
CnC
Anonymous
1578
The Lady of May
LMay
Philip Sidney
1578
The Entertainment at Norwich
ENor
Thomas Churchyard
1578
Mercury and Virtue
Merc
Thomas Salter
1579
Wit and Will
WitW
Nicholas Breton
1580
The Soldier and the Scholar
SolS
Nicholas Breton
1580
A Dialogue between Anger and Patience
DAnP
Nicholas Breton
1580
The Three Ladies of London
3LL
Robert Wilson
1581
Thebais
Theb
Seneca; Thomas Newton (trans.)
1581
Antigone
Antg
Sophocles; Thomas Watson (trans.)
1581
The Rare Triumphs of Love and Fortune
LFor
Anonymous
1582
Fedele and Fortunio (The Two Italian Gentlemen)
FedF
Anthony Munday
1583
Campaspe
Camp
John Lyly
1583
The Devil and Dives
DDiv
Thomas Lupton
1583
A Pedlar’s Tale
PedT
Anonymous
1584
The Arraignment of Paris
APar
George Peele
1584
Philomathes’ Dream
PhD
John Harrison
1584
Sappho and Phao
SaP
John Lyly
1584
Galatea (Gallathea)
Gal
John Lyly
1584
Philotus
Ptus
Alexander Montgomerie
1585
The Famous Victories of Henry V (The Famous Victories of Henry the Fifth)
FV
Anonymous
1586
Philomathes’ Second Dream
Ph2D
John Harrison
1586
1 Tamburlaine (Tamburlaine the Great, Part One)
1Tam
Christopher Marlowe
1587
2 Tamburlaine (Tamburlaine the Great, Part Two)
2Tam
Christopher Marlowe
1587
Alphonsus, King of Aragon
AKA
Robert Greene
1587
Andria (The Woman from Andros)
And
Terence; Maurice Kyffin (trans.)
1587
The Spanish Tragedy
SpT
Thomas Kyd
1587
The Wars of Cyrus
WCyr
Anonymous
1588
Doctor Faustus
DFau
Christopher Marlowe
1588
Dido, Queen of Carthage
DQC
Christopher Marlowe; Thomas Nashe
1588
The Battle of Alcazar
BAlc
George Peele
1588
Endymion
End
John Lyly
1588
The Woman in the Moon
WMn
John Lyly
1588
The Three Lords and Three Ladies of London
3L3LL
Robert Wilson
1588
The Misfortunes of Arthur
MArt
Thomas Hughes; Nicholas Trotte; Francis Flower; Christopher Yelverton; Francis Bacon;
John Lancaster
1588
Soliman and Perseda
SolP
Thomas Kyd
1588
The Wounds of Civil War
WCW
Thomas Lodge
1588
King Leir
Leir
Anonymous
1589
The True Tragedy of Richard III (The True Tragedy of Richard the Third)
TTR3
Anonymous
1589
The Jew of Malta
JewM
Christopher Marlowe
1589
The Troublesome Reign of King John
TRKJ
George Peele
1589
Mother Bombie
MBom
John Lyly
1589
Midas
Mid
John Lyly
1589
Friar Bacon and Friar Bungay
FBFB
Robert Greene
1589
A Looking Glass for London and England
LGLE
Thomas Lodge; Robert Greene
1589
Rowland’s Godson
RowG
Anonymous
1590
Fair Em
FEm
Anonymous
1590
Jack Straw
JStr
Anonymous
1590
Arden of Faversham
Ardn
Anonymous; William Shakespeare
1590
John a Kent and John a Cumber
JKJC
Anthony Munday
1590
David and Bethsabe (David and Bathsheba)
DavB
George Peele
1590
Love’s Metamorphosis
LMet
John Lyly
1590
Antonius
Anto
Robert Garnier; Mary Herbert (trans.)
1590
The Scottish History of James IV (James the Fourth)
J4
Robert Greene
1590
Mucedorus
Mucd
Anonymous
1591
Locrine
Loc
Anonymous
1591
George-a-Greene
GaG
Anonymous
1591
John of Bordeaux
JBor
Anonymous
1591
Edward I (Edward the First)
E1
George Peele
1591
Descensus Astraeae
DecA
George Peele
1591
Orlando Furioso
Orl
Robert Greene
1591
Selimus
Sel
Robert Greene
1591
Amyntas
Amyn
Torquato Tasso; Abraham Fraunce (trans.)
1591
2 Henry VI (The First Part of the Contention) (Henry the Sixth, Part Two)
2H6
William Shakespeare
1591
3 Henry VI (Richard, Duke of York) (Henry the Sixth, Part Three)
3H6
William Shakespeare
1591
A Knack to Know a Knave
KnKn
Anonymous
1592
Edward II (Edward the Second)
E2
Christopher Marlowe
1592
Jig of Averted Adultery (Francis and Richard)
AvAd
George Attwell?
1592
The Old Wife’s Tale (The Old Wives Tale)
OWT
George Peele
1592
Menaechmi (The Menaechmuses)
Mena
Plautus; William Warner (trans.)
1592
The Cobbler’s Prophecy
CobP
Robert Wilson
1592
Summer’s Last Will and Testament
SLW
Thomas Nashe
1592
1 Henry VI (Henry the Sixth, Part One)
1H6
Thomas Nashe; William Shakespeare; Christopher Marlowe
1592
The Taming of the Shrew
Shr
William Shakespeare
1592
Titus Andronicus
Tit
William Shakespeare; George Peele
1592
The Massacre at Paris
MaP
Christopher Marlowe
1593
Cleopatra
Cleo
Samuel Daniel
1593
The Comedy of Errors
Err
William Shakespeare
1593
Richard III (Richard the Third)
R3
William Shakespeare
1593
Edward III (Edward the Third)
E3
William Shakespeare?
1593
The Taming of a Shrew
AShr
Anonymous
1594
A Knack to Know an Honest Man
KKHM
Anonymous
1594
Gesta Grayorum
GesG
Anonymous
1594
Cornelia
Corn
Robert Garnier; Thomas Kyd (trans.)
1594
The Two Gentlemen of Verona
TGV
William Shakespeare
1594
Jig of an Amorous Cobbler
AmCb
Anonymous
1595
Jig of Rustic Wooing
JRW
Anonymous
1595
The Blackman
JBm
Anonymous
1595
Of Love and Self-Love
OLSL
Francis Bacon
1595
The Masque of Proteus
MPro
Francis Davison; Thomas Campion
1595
Two Lamentable Tragedies
TLT
Robert Yarington
1595
Singing Simpkin
SngS
Will Kempe?
1595
Romeo and Juliet
Rom
William Shakespeare
1595
Richard II (Richard the Second)
R2
William Shakespeare
1595
A Midsummer Night’s Dream
MND
William Shakespeare
1595
Mustapha
Must
Fulke Greville
1596
The Blind Beggar of Alexandria
BBA
George Chapman
1596
Captain Thomas Stukely
Stuk
Thomas Heywood
1596
Love’s Labour’s Lost
LLL
William Shakespeare
1596
King John
Jn
William Shakespeare
1596
The Merchant of Venice
MV
William Shakespeare
1596
Edmund Ironside
Edm
Anonymous
1597
A Warning for Fair Women
WFW
Anonymous
1597
The Case is Altered
Case
Ben Jonson
1597
A Humorous Day’s Mirth
AHDM
George Chapman
1597
1 Henry IV (Henry the Fourth, Part One)
1H4
William Shakespeare
1597
The Merry Wives of Windsor
MWW
William Shakespeare
1597
2 Henry IV (Henry the Fourth, Part Two)
2H4
William Shakespeare
1597
2 Robin Hood (The Death of Robert, Earl of Huntingdon)
2RH
Anthony Munday; Henry Chettle
1598
1 Robin Hood (The Downfall of Robert, Earl of Huntingdon)
1RH
Anthony Munday; Henry Chettle?
1598
Every Man in His Humour
EMI
Ben Jonson
1598
The Spanish Bawd
SpBd
Ferdinand de Rojas; James Mabbe (trans.)
1598
The Two Angry Women of Abingdon
2AWA
Henry Porter
1598
The Virtuous Octavia
VOct
Samuel Brandon
1598
Eunuch
Eun
Terence; Richard Bernard (trans.)
1598
Adelphos (The Brothers)
Adel
Terence; Richard Bernard (trans.)
1598
Heautontimorumenon (The Self-Tormentor)
Heau
Terence; Richard Bernard (trans.)
1598
Hecyra
Hecy
Terence; Richard Bernard (trans.)
1598
Phormio
Phor
Terence; Richard Bernard (trans.)
1598
Englishmen for My Money (A Woman Will Have Her Will)
EFMM
William Haughton
1598
Much Ado About Nothing
Ado
William Shakespeare
1598
The Pilgrimage to Parnassus
PPar
Anonymous
1599
Look About You
LAY
Anonymous
1599
A Larum for London
ALLn
Anonymous
1599
The Weakest Goeth to the Wall
Weak
Anonymous
1599
The Trial of Chivalry
TrCh
Anonymous
1599
Sir John Oldcastle
SJO
Anthony Munday; Michael Drayton; Robert Wilson; Richard Hathway
1599
Every Man Out of His Humour
EMO
Ben Jonson
1599
Antonio and Mellida (Antonio and Mellida, Part 1
AntM
John Marston
1599
Thenot and Piers
ThnP
Mary Herbert
1599
The Shoemaker’s Holiday (The Gentle Craft)
Shoe
Thomas Dekker
1599
Old Fortunatus
OFor
Thomas Dekker
1599
1 Edward IV (Edward the Fourth, Part One)
1H4
Thomas Heywood
1599
2 Edward IV (Edward the Fourth, Part Two)
2H4
Thomas Heywood
1599
Henry V (Henry the Fifth)
H5
William Shakespeare
1599
Julius Caesar
JC
William Shakespeare
1599
1 The Return from Parnassus (The Return from Parnassus, Part One)
1RP
Anonymous
1600
The Wisdom of Doctor Dodypoll
WDD
Anonymous
1600
The Maid’s Metamorphosis
MMet
Anonymous
1600
Club Law
Club
Anonymous
1600
1 Hieronimo (Hieronimo, Part One)
1Hrn
Anonymous
1600
Oedipus (Yale MS Eliz 294)
YOed
Aristotle Knowsley
1600
Cynthia’s Revels
CynR
Ben Jonson
1600
Alaham
Alhm
Fulke Greville
1600
Patient Grissil
PatG
Henry Chettle; Thomas Dekker; William Haughton
1600
The Blind Beggar of Bethnal Green
BBBG
John Day
1600
Jack Drum’s Entertainment
JDrm
John Marston
1600
Antonio’s Revenge (Antonio and Mellida, Part Two)
AntR
John Marston
1600
Lust’s Dominion (The Spanish Moor’s Tragedy)
LDom
Thomas Dekker; William Haughton; John Day; Christopher Marlowe?
1600
The Devil and His Dame (Grim, the Collier of Croydon)
Grim
William Haughton
1600
As You Like It
AYL
William Shakespeare
1600
Hamlet
Ham
William Shakespeare
1600
The Contention between Liberality and Prodigality
CLP
Anonymous
1601
Thomas, Lord Cromwell
TLC
Anonymous
1601
Sir Thomas More
STM
Anthony Munday
1601
Poetaster
Poet
Ben Jonson
1601
Jig of Michael and Frances
JMF
Francis Mitchell
1601
The Faithful Shepherd (Il pastor fido)
IPF
Giambattista Guarini; Tailboys Dymoke (trans.)
1601
What You Will
WYW
John Marston
1601
Satiromastix
Stmx
Thomas Dekker
1601
Blurt, Master Constable
BMC
Thomas Dekker
1601
How a Man May Choose a Good Wife from a Bad
HMMC
Thomas Heywood
1601
Change is No Robbery (The Cucqueans and Cuckolds Errants)
CNR
William Percy
1601
Muhammad and His Heaven
MHH
William Percy
1601
Twelfth Night
TN
William Shakespeare
1601
2 The Return from Parnassus (The Return from Parnassus, Part Two)
2RP
Anonymous
1602
Wily Beguiled
WBeg
Anonymous; Samuel Rowley?
1602
The Fair Maid of the Exchange
FMEx
Anonymous; Thomas Heywood?
1602
Sir Giles Goosecap
SGG
George Chapman
1602
The Gentleman Usher
GenU
George Chapman
1602
Histriomastix
Hstx
John Marston
1602
A Dialogue between Three Philosophers
D3Ph
Nicholas Breton
1602
A Merry Dialogue betwixt the Taker and Mistaker
DTkM
Nicholas Breton
1602
’Tis Merry when Gossips Meet
TMGM
Samuel Rowlands
1602
Sir Thomas Wyatt
STW
Thomas Dekker; John Webster; Thomas Heywood?; Henry Chettle?
1 If You Know Not Me, You Know Nobody (If You Know Not Me, You Know Nobody, Part One)
1IYK
Thomas Heywood
1604
2 If You Know Not Me, You Know Nobody (If You Know Not Me, You Know Nobody, Part Two)
2IYK
Thomas Heywood
1604
The Phoenix
Phnx
Thomas Middleton
1604
Michaelmas Term
MsTm
Thomas Middleton
1604
Croesus
Croe
William Alexander
1604
Othello (The Moor of Venice)
Oth
William Shakespeare
1604
Caesar and Pompey
CPom
Anonymous
1605
Nobody and Somebody
Nbdy
Anonymous
1605
Claudius Tiberius Nero
CTN
Anonymous
1605
The Triumphs of Reunited Britannia
TRBr
Anthony Munday
1605
The Masque of Blackness
MBla
Ben Jonson
1605
Eastward Ho!
EHo
Ben Jonson; George Chapman; John Marston
1605
The Tragedy of Mariam (Mariam, Queen of Jewry)
TMar
Elizabeth Cary
1605
The Widow’s Tears
WidT
George Chapman
1605
Monsieur D’Olive
MonD
George Chapman
1605
The Fawn (Parasitaster)
Fwn
John Marston
1605
The Wonder of Women (Sophonisba)
WonW
John Marston
1605
Arcadia Reformed
ArcR
Samuel Daniel
1605
2 The Honest Whore (The Honest Whore, Part Two)
2HW
Thomas Dekker
1605
Northward Ho!
NHo
Thomas Dekker; John Webster
1605
A Trick to Catch the Old One
TCOO
Thomas Middleton
1605
A Mad World, My Masters
MWMM
Thomas Middleton
1605
A Yorkshire Tragedy
YorT
Thomas Middleton
1605
All’s Well That Ends Well
AWW
William Shakespeare
1605
King Lear
Lr
William Shakespeare
1605
The Birth of Hercules
BirH
Anonymous
1606
The Devil’s Charter
DevC
Barnabe Barnes
1606
Hymenaei
Hymn
Ben Jonson
1606
The Barriers (Truth versus Opinion)
Brrs
Ben Jonson
1606
Volpone (The Fox)
Volp
Ben Jonson
1606
A Dialogue of Fish-Eating
DFsh
Desiderius Erasmus; William Burton (trans.)
1606
Naufragium (The Shipwreck)
Nauf
Desiderius Erasmus; William Burton (trans.)
1606
A Dialogue between a Good Woman and a Shrew
DGWS
Desiderius Erasmus; William Burton (trans.)
1606
Dialogue between a Harlot and a Godly Young Man
DHar
Desiderius Erasmus; William Burton (trans.)
1606
A Dialogue of a Woman in Child-Bed
DWCB
Desiderius Erasmus; William Burton (trans.)
1606
A Dialogue of a Popish Pilgrimage
DPP
Desiderius Erasmus; William Burton (trans.)
1606
A Dialogue of a Popish Funeral
DPF
Desiderius Erasmus; William Burton (trans.)
1606
The Fleer
Flr
Edward Sharpham
1606
The Woman-Hater
WomH
Francis Beaumont; John Fletcher
1606
The Wars of Caesar and Pompey
WCP
George Chapman
1606
The Miseries of Enforced Marriage
MEM
George Wilkins
1606
The Isle of Gulls
Gull
John Day
1606
The Whore of Babylon
WoB
Thomas Dekker
1606
The Royal King and the Loyal Subject
RKLS
Thomas Heywood
1606
The Puritan (The Puritan Widow)
Pur
Thomas Middleton
1606
The Revenger’s Tragedy
RevT
Thomas Middleton
1606
Lingua
Ling
Thomas Tomkis
1606
The Entertainment at Theobalds
ETbd
Thomas Wilson; Ben Jonson; John Gordon
1606
Macbeth
Mac
William Shakespeare
1606
Antony and Cleopatra
Ant
William Shakespeare
1606
The Great Cham
GChm
Anonymous
1607
The Royal Entertainment at Theobalds
RETh
Ben Jonson
1607
Cupid’s Whirligig
CupW
Edward Sharpham
1607
The Knight of the Burning Pestle
KBP
Francis Beaumont
1607
Cupid’s Revenge
CupR
Francis Beaumont; John Fletcher
1607
The Travels of the Three English Brothers
TTEB
George Wilkins; John Day; William Rowley
1607
The Dumb Knight
DmKn
Gervase Markham; Lewis Machin
1607
Humour Out of Breath
HumB
John Day
1607
Masque at Ashby
MAsh
John Marston
1607
The Turk
Turk
John Mason
1607
Every Woman in Her Humour
EWI
Lewis Machin
1607
The Family of Love
FamL
Lording Barry
1607
Lord Hayes’ Masque
LHM
Thomas Campion
1607
The Rape of Lucrece
RLuc
Thomas Heywood
1607
Your Five Gallants
YFG
Thomas Middleton
1607
The Alexandraean Tragedy
Alex
William Alexander
1607
The Tragedy of Julius Caesar
TJC
William Alexander
1607
Pericles, Prince of Tyre
Per
William Shakespeare; George Wilkins
1607
Timon of Athens
Tim
William Shakespeare; Thomas Middleton
1607
Time’s Complaint
TimC
Anonymous
1608
The Seven Days of the Week
SDW
Anonymous
1608
The Christmas Prince
ChPr
Anonymous
1608
The Masque of Beauty
MBea
Ben Jonson
1608
The Hue and Cry after Cupid
HCC
Ben Jonson
1608
Byron’s Conspiracy (The Conspiracy of Charles, Duke of Byron) (Biron’s Conspiracy)
ByrC
George Chapman
1608
Byron’s Tragedy (The Tragedy of Charles, Duke of Byron) (Biron’s Tragedy)
ByrT
George Chapman
1608
The Faithful Shepherdess
FShp
John Fletcher
1608
Periander
Peri
John Sansbury?
1608
Ram Alley
RamA
Lording Barry
1608
The Two Maids of Mortlake
Mlake
Robert Armin
1608
Coriolanus
Cor
William Shakespeare
1608
Camp Bell
CB
Anthony Munday
1609
The Masque of Queens
MQns
Ben Jonson
1609
Entertainment at Britain’s Burse
EBB
Ben Jonson
1609
Philaster
Phil
Francis Beaumont; John Fletcher
1609
The Coxcomb
Coxc
Francis Beaumont; John Fletcher
1609
A Woman is a Weathercock
WomW
Nathan Field
1609
London’s Love to Prince Henry
LLPH
Anthony Munday
1610
Prince Henry’s Barriers
PHB
Ben Jonson
1610
Epicene (The Silent Woman) (Epicoene)
Epic
Ben Jonson
1610
The Alchemist
Alch
Ben Jonson
1610
The Atheist’s Tragedy
AthT
Cyril Tourneur
1610
A Looking Glass for Married Folks
LGMF
Desiderius Erasmus; Robert Snawsel (trans.)
1610
The Revenge of Bussy D’Ambois
RBDA
George Chapman
1610
The Woman’s Prize (The Tamer Tamed)
WomP
John Fletcher
1610
The Scornful Lady
SLdy
John Fletcher; Francis Beaumont
1610
Masque of Fairies
MFrs
John Sylvester
1610
Amends for Ladies
AmL
Nathan Field
1610
Chester’s Triumph
ChsT
Robert Amory
1610
Tethys’ Festival
Teth
Samuel Daniel
1610
The Bloody Banquet
BBan
Thomas Dekker; Thomas Middleton
1610
1 The Fair Maid of the West (The Fair Maid of the West, Part One)
1FMW
Thomas Heywood
1610
The Insatiate Countess
InsC
William Barkstead; Lewis Machin; John Marston
1610
Cymbeline
Cym
William Shakespeare
1610
Alice and Alexis (Stella and Alexis)
AlAl
Anonymous
1611
The Valiant Welshman (Caradoc the Great)
ValW
Anonymous; R. A.
1611
Chruso-Thriambos
ChTh
Anthony Munday
1611
Oberon (The Masque of Oberon)
MOb
Ben Jonson
1611
Love Freed from Ignorance and Folly
LFIF
Ben Jonson
1611
Catiline’s Conspiracy (Catiline His Conspiracy)
Cat
Ben Jonson
1611
A King and No King
KNK
Francis Beaumont; John Fletcher
1611
The Maid’s Tragedy
MT
Francis Beaumont; John Fletcher
1611
The City Gallant (Greene’s Tu Quoque)
CGal
John Cooke
1611
A Christian Turned Turk
CTTu
Robert Daborne
1611
Thomas of Woodstock
TW
Samuel Rowley
1611
If It Be Not Good, The Good Devil Is In It (If This Be Not A Good Play, the Devil is in It)
IBNG
Thomas Dekker
1611
The Roaring Girl (Moll Cutpurse)
Roar
Thomas Dekker; Thomas Middleton
1611
The Golden Age
GldA
Thomas Heywood
1611
The Silver Age
SlvA
Thomas Heywood
1611
The Brazen Age
BrzA
Thomas Heywood
1611
No Wit, No Help Like a Woman’s
NWNH
Thomas Middleton
1611
The Second Maiden’s Tragedy
2MT
Thomas Middleton
1611
The Winter’s Tale
WT
William Shakespeare
1611
The Tempest
Tmp
William Shakespeare
1611
A Dialogue between Gown, Hood, and Cap
DGHC
Anonymous
1612
Love Restored
LovR
Ben Jonson
1612
Chabot, Admiral of France
Chbt
George Chapman; James Shirley
1612
The Captain
Cptn
John Fletcher; Francis Beaumont
1612
Henry VIII (All is True) (Henry the Eighth)
H8
John Fletcher; William Shakespeare
1612
The White Devil
WDev
John Webster
1612
Troia-Nova Triumphans
TNT
Thomas Dekker
1612
Cardenio (Double Falsehood)
Cdno
William Shakespeare; John Fletcher
1612
Tom o’ Lincoln (Tom a Lincoln)
ToL
Anonymous
1613
A Challenge at Tilt
CTil
Ben Jonson
1613
The Irish Masque
Irsh
Ben Jonson
1613
The Masque of the Inner Temple and Gray’s Inn
MITG
Francis Beaumont
1613
The Middle Temple and Lincoln’s Inn Masque
MTLI
George Chapman
1613
The Two Noble Kinsmen
TNK
John Fletcher; William Shakespeare
1613
Cynthia’s Revenge (Menander’s Ecstasy)
MenE
John Stephens
1613
The Duchess of Malfi
DMal
John Webster
1613
Four Plays, or Moral Representations, in One
FPI1
Nathan Field; John Fletcher
1613
The Honest Man’s Fortune
HMF
Nathan Field; John Fletcher; Philip Massinger; Robert Daborne
1613
The Hog Hath Lost His Pearl
Hog
Robert Tailor
1613
The Masque of Lords
MLrd
Thomas Campion
1613
The Entertainment at Caversham
ECav
Thomas Campion
1613
The Somerset Masque
MSom
Thomas Campion
1613
1 The Iron Age (The Iron Age, Part One)
1IrA
Thomas Heywood
1613
2 The Iron Age (The Iron Age, Part Two)
2IrA
Thomas Heywood
1613
A Chaste Maid in Cheapside
CMC
Thomas Middleton
1613
Civic Entertainment at Islington (The New River Entertainment)
CEI
Thomas Middleton
1613
The Triumphs of Truth
TTru
Thomas Middleton; Anthony Munday?
1613
Wit at Several Weapons
WSW
Thomas Middleton; William Rowley
1613
The Hector of Germany (The Palsgrave)
Hect
William Smith?
1613
The Masque of Flowers
MFlw
Anonymous
1614
A Merry Dialogue between A Band, Cuff, and Ruff
BCR
Anonymous
1614
Work for Cutlers
WCut
Anonymous
1614
Boot and Spur
Boot
Anonymous
1614
The Honest Lawyer
HLaw
Anonymous; S. S.
1614
Himatia-Poleos (The Triumphs of Old Drapery)
HimP
Anthony Munday
1614
The Tilting (Eros and Anteros)
Tilt
Ben Jonson
1614
Bartholomew Fair
Bart
Ben Jonson
1614
Valentinian
Val
John Fletcher
1614
Bonduca
Bon
John Fletcher
1614
Wit Without Money
WWM
John Fletcher
1614
Hymen’s Triumph
HymT
Samuel Daniel
1614
Masque of Ulysses and Circe (The Masque of the Inner Temple)
MUC
Anonymous
1615
The Cold Year
ColY
Anonymous
1615
Metropolis Coronata (The Triumphs of Ancient Drapery)
MetC
Anthony Munday
1615
Mercury Vindicated from the Alchemists at Court
MVin
Ben Jonson
1615
Monsieur Thomas (Father’s Own Son)
MTho
John Fletcher
1615
The Night-Walkers (The Night-Walker) (The Little Thief)
NW
John Fletcher; James Shirley
1615
Love’s Cure
LCur
John Fletcher; Philip Massinger?
1615
Sicelides (The Sicilians)
Sic
Phineas Fletcher
1615
The Widow
Wid
Thomas Middleton
1615
Albumazar
Albz
Thomas Tomkis
1615
Thorney Abbey
ThAb
William Rowley?
1615
Work for Jupiter
WJup
Anonymous
1616
Occasion, Truth, and Knights (Barriers Entertainment)
OTK
Anonymous
1616
Chrysanaleia (The Golden Fishing)
CTGF
Anthony Munday
1616
The Golden Age Restored
GAR
Ben Jonson
1616
The Devil is an Ass
DevA
Ben Jonson
1616
Love’s Pilgrimage
LPil
John Fletcher
1616
The Mad Lover
MadL
John Fletcher
1616
Beggars’ Bush
BegB
John Fletcher; Philip Massinger
1616
The Poor Man’s Comfort
PMC
Robert Daborne
1616
The Witch
Wch
Thomas Middleton
1616
Civitatis Amor
CivA
Thomas Middleton
1616
A Fair Quarrel
FQ
Thomas Middleton; William Rowley
1616
Dialogue between Alexander the Great and Diogenes
DAGD
William Goddard
1616
Pathomachia
Path
Ambrose Fisher?
1617
The Play of Poor (The Comedy of Poor)
Poor
Anonymous
1617
The Genius of the River Ouse (Royal Entertainment at York)
Ouse
Anonymous
1617
Royal Entertainment at Hoghton Tower (Two Gods)
REHT
Anonymous
1617
Christmas His Masque (Christmas’s Masque)
CHM
Ben Jonson
1617
The Vision of Delight
VoD
Ben Jonson
1617
The Masque of Lethe
MLth
Ben Jonson
1617
Christening Entertainment at Blackfriars
ChBF
Ben Jonson
1617
Hans Beer-Pot (See Me and See Me Not)
HBP
Daubridgcourt Belchier
1617
The Chances
Chan
John Fletcher
1617
Rollo (The Bloody Brother)
Rol
John Fletcher; Philip Massinger
1617
Thierry and Theodoret
TT
John Fletcher; Philip Massinger; Anonymous
1617
Love’s Victory
LVic
Mary Wroth
1617
The Court and Country
CoCo
Nicholas Breton
1617
The Queen of Corinth
QCor
Philip Massinger; Nathan Field; John Fletcher
1617
A Dialogue betwixt Nature and Time
DNT
Robert Anton
1617
Cupid’s Banishment
CupB
Robert White
1617
Masque at Brougham Castle
MBC
Thomas Dekker
1617
The Raging Turk
RTrk
Thomas Goffe
1617
The Triumphs of Honour and Industry
THI
Thomas Middleton
1617
Royal Entertainment at Linlithgow (A Lion)
REL
William Drummond
1617
Swetname, The Woman-Hater, Arraigned by Women
Swet
Anonymous
1618
Masque of Mountebanks and Knights (The Masque of Gray’s Inn)
MMK
Anonymous
1618
Charlemagne (The Distracted Emperor)
Chrl
Anonymous
1618
Sidero-Thriambos
SdTh
Anthony Munday
1618
The Marriage of the Arts
MarA
Barten Holyday
1618
Pleasure Reconciled to Virtue
PRV
Ben Jonson
1618
For the Honour of Wales (The Goats’ Masque)
HWal
Ben Jonson
1618
The Loyal Subject
LSub
John Fletcher
1618
The Elder Brother
EldB
John Fletcher; Philip Massinger
1618
The Devil’s Law-Case (When Women Go to Law)
DLC
John Webster
1618
The Knight of Malta
KMal
Nathan Field; John Fletcher; Philip Massinger
1618
Masque of Virtues and Hospitality
MVH
Thomas Pestell?
1618
A Shoemaker, a Gentleman
ShGn
William Rowley
1618
A Christmas Mess
CMss
Anonymous
1619
Two Wise Men and All the Rest Fools
TWM
Anonymous
1619
Nero (Piso’s Conspiracy)
Nero
Anonymous
1619
The Lovesick King
LovK
Anthony Brewer
1619
Masque of the Twelve Months (The Prince’s Christmas Masque)
M12M
George Chapman?
1619
Herod and Antipater
HA
Gervase Markham; William Sampson
1619
The Two Merry Milkmaids
TMM
J. C.; Anonymous
1619
Fuimus Troes (The True Trojans)
FuTr
Jasper Fisher
1619
Demetrius and Enanthe (The Humorous Lieutenant)
DemE
John Fletcher
1619
Sir John van Oldenbarnevelt
SJVO
John Fletcher; Philip Massinger
1619
The Pope’s Advice to His Sons (A Conference held at Angelo Castle)
PAHS
John Taylor; Anonymous
1619
The Custom of the Country
CuCo
Philip Massinger; John Fletcher
1619
The Fatal Dowry
FDow
Philip Massinger; Nathan Field
1619
Medea
Mede
Seneca; Anonymous (trans.)
1619
The Courageous Turk (Amurath)
CTrk
Thomas Goffe
1619
The Careless Shepherdess
CShp
Thomas Goffe
1619
The Masque of Heroes
MHer
Thomas Middleton
1619
The Triumphs of Love and Antiquity
TLA
Thomas Middleton
1619
All’s Lost by Lust
ALBL
William Rowley
1619
The Old Law (A New Way to Please You)
OldL
William Rowley; Thomas Middleton
1619
The Costly Whore
CosW
Anonymous
1620
Guy, Earl of Warwick
Guy
Anonymous
1620
The Faithful Friends
FF
Anonymous
1620
News from the New World Discovered in the Moon
NNW
Ben Jonson
1620
Women Pleased
WP
John Fletcher
1620
The Little French Lawyer
LFL
John Fletcher; Philip Massinger
1620
The False One
FO
John Fletcher; Philip Massinger
1620
The Running Masque
RunM
John Maynard?
1620
Tes Irenes Trophaea (The Triumphs of Peace)
TPea
John Squire
1620
The Laws of Candy
LCan
Philip Massinger; John Ford; John Fletcher?
1620
The Sophister (Fallacy)
Sphr
Richard Zouche
1620
The Virgin Martyr
VirM
Thomas Dekker; Philip Massinger
1620
Orestes
Ores
Thomas Goffe
1620
The Heir
Heir
Thomas May
1620
The Cock (The Entertainment at Sir William Cokayne’s House)
Cock
Thomas Middleton
1620
The Mayor of Queenborough (Hengist, King of Kent)
Heng
Thomas Middleton
1620
The Archer (The Entertainment at Bunhill on the Shooting Day)
Arch
Thomas Middleton
1620
The Water Nymph (The Entertainment at the Conduit Head)
WatN
Thomas Middleton
1620
A Mourner (The Year’s Funeral)
Mour
Thomas Middleton
1620
The Servant of Comus (The Entertainment at Sir Francis Jones’s Welcome)
SCom
Thomas Middleton
1620
The Triumph of Temperance (Levity and Temperance)
TTem
Thomas Middleton
1620
The World Tossed at Tennis
WTT
Thomas Middleton; William Rowley
1620
Fool’s Fortune
FoFo
Anonymous
1621
The Two Noble Ladies and the Converted Conjuror
TNL
Anonymous
1621
Pan’s Anniversary
PanA
Ben Jonson
1621
The Gypsies Metamorphosed
GypM
Ben Jonson
1621
The Essex House Masque
MEH
George Chapman?
1621
The Island Princess
IP
John Fletcher
1621
The Wild-Goose Chase
WGC
John Fletcher
1621
The Pilgrim
Pil
John Fletcher
1621
The Witch of Edmonton
WEd
John Ford; Thomas Dekker; William Rowley
1621
The Duke of Milan
DMil
Philip Massinger
1621
Masque of Goddesses
MGds
Thomas Carew?
1621
Match Me in London
MML
Thomas Dekker
1621
The Four Seasons (The Entertainment at Sir Francis Jones’s at Easter)
FSFJ
Thomas Middleton
1621
Flora’s Welcome
FloW
Thomas Middleton
1621
Flora and Her Servants
FloS
Thomas Middleton
1621
Women, Beware Women
WBW
Thomas Middleton
1621
More Dissemblers Besides Women
MDBW
Thomas Middleton
1621
The Sun in Aries
SunA
Thomas Middleton; Anthony Munday
1621
The Thracian Wonder
ThrW
William Rowley
1621
The Entertainment for the General Training (Pallas)
EGTP
Thomas Middleton
1621
The Fatal Marriage (A Second Lucretia)
FMar
Anonymous
1622
The Masque of Augurs
MAug
Ben Jonson
1622
The Martyred Soldier
MarS
Henry Shirley
1622
The Double Marriage
DMar
John Fletcher; Philip Massinger
1622
The Prophetess
Prop
John Fletcher; Philip Massinger
1622
The Spanish Curate
SpCu
John Fletcher; Philip Massinger
1622
Osman the Great Turk (The Noble Servant)
Osm
Lodowick Carlell
1622
The Sea Voyage
SV
Philip Massinger; John Fletcher
1622
The Wonder of a Kingdom
WonK
Thomas Dekker
1622
The Noble Spanish Soldier
NSS
Thomas Dekker
1622
Honour
Hon
Thomas Middleton
1622
The Triumphs of Honour and Virtue
THV
Thomas Middleton
1622
The Nice Valour
NVal
Thomas Middleton; John Fletcher?
1622
Anything for a Quiet Life
AQL
Thomas Middleton; John Webster
1622
The Changeling
Chng
Thomas Middleton; William Rowley
1622
A Match at Midnight
MatM
W. R.; Anonymous
1622
The Birth of Merlin (The Child Hath Found His Father)
BMer
William Rowley
1622
Time Vindicated to Himself and to His Honours
TVin
Ben Jonson
1623
Alopichos (The Fox)
Alop
James Cobbes
1623
The Bondman (The Noble Bondman)
Bdmn
Philip Massinger
1623
A Very Woman (The Prince of Tarent)
VerW
Philip Massinger; John Fletcher
1623
The Lovers’ Progress (The Wandering Lovers)
LovP
Philip Massinger; John Fletcher
1623
A Knot of Fools
Knot
Thomas Brewer
1623
The Welsh Ambassador
WAm
Thomas Dekker
1623
The Spanish Gypsy
SGyp
Thomas Dekker; John Ford; Thomas Middleton; William Rowley
1623
The Wise Woman of Hoxton (The Wise Woman of Hogsdon)
WWH
Thomas Heywood
1623
Fortune by Land and Sea
FLS
Thomas Heywood; William Rowley
1623
The Triumphs of Integrity
IntT
Thomas Middleton; Anthony Munday
1623
The Fairy Knight
FK
Thomas Randolph?
1623
The Maid of the Mill (The Maid in the Mill)
MMil
William Rowley; John Fletcher
1623
The Stonyhurst Pageants
SHP
Anonymous
1624
Lord Gray’s Masque
LGM
Anonymous
1624
The Packman’s Pater Noster
PmPN
Anonymous; James Sempill (trans.)
1624
Neptune’s Triumph for the Return of Albion
NepT
Ben Jonson
1624
The Masque of Owls
MOwl
Ben Jonson
1624
The Romanus Tragedy of
Rmns
James Cobbes
1624
A Wife for a Month
WFAM
John Fletcher
1624
Rule a Wife and Have a Wife
RWHW
John Fletcher
1624
The Sun’s Darling
SunD
John Ford; Thomas Dekker
1624
Fidelia and Glausamond (Tancred and Ghismonda)
FidG
John Newdigate
1624
Monuments of Honour
MonH
John Webster
1624
Nebuchadnezzar’s Fiery Furnace
NebF
Joshua Sylvester?
1624
The Renegado (The Gentleman of Venice)
Ren
Philip Massinger
1624
The Parliament of Love
ParL
Philip Massinger
1624
The City Nightcap
CitN
Robert Davenport
1624
The Duchess of Suffolk
DSuf
Thomas Drue
1624
The English Traveller
ETrv
Thomas Heywood
1624
The Captives (The Lost Recovered)
Cptv
Thomas Heywood
1624
A Game at Chess
GCh
Thomas Middleton
1624
A Cure for a Cuckold (A Wedding)
CFAC
William Rowley; John Webster; Thomas Heywood
1624
A New Wonder (A Woman Never Vexed)
WNV
William Rowley; Thomas Heywood?
1624
Wine, Beer, and Ale
WBA
Anonymous
1625
The Fortunate Isles and Their Union
FITU
Ben Jonson
1625
Love Tricks (The School of Compliment)
LovT
James Shirley
1625
The Theatre of Apollo
TAp
John Beaumont
1625
The Telltale (The Tell-Tale)
Tell
Anonymous
1626
The Staple of News
Stap
Ben Jonson
1626
The Duke of Lerma (The Great Favourite)
Lerm
Henry Shirley
1626
The Knave in Grain, New Vamped
KnaG
J. D.; Anonymous
1626
The Valiant Scot
VSct
J. W.; Anonymous
1626
The Maid’s Revenge
MRev
James Shirley
1626
The Wedding (Hymenaeus)
SWed
James Shirley
1626
The Parliament of Bees
Bees
John Day
1626
The Noble Gentleman
NGen
John Fletcher
1626
The Fair Maid of the Inn
FMI
John Webster; Philip Massinger; John Ford; John Fletcher
1626
Appius and Virginia
AppV
John Webster; Thomas Heywood
1626
A New Way to Pay Old Debts
NWP
Philip Massinger
1626
The Unnatural Combat
UnCo
Philip Massinger
1626
The Roman Actor
RAct
Philip Massinger
1626
A New Trick to Cheat the Devil
NTCD
Robert Davenport
1626
Dick of Devonshire
DDev
Thomas Heywood
1626
Cleopatra, Queen of Egypt
CQE
Thomas May
1626
The Triumphs of Health and Prosperity
THP
Thomas Middleton
1626
Aristippus (The Jovial Philosopher)
Aris
Thomas Randolph
1626
Albovine, King of the Lombards
Albv
William Davenant
1626
Musophilus (Wise Men Have Fools About Them)
Muso
Anonymous
1627
The Queen (The Excellency of Her Sex)
QEHS
John Ford
1627
The Great Duke (The Great Duke of Florence)
GDuk
Philip Massinger
1627
The May Masque (May Day Show at Apethorpe Hall)
MMay
Rachel Fane
1627
The Andrian Woman
AndW
Terence; Thomas Newman (trans.)
1627
The Eunuch
Eunu
Terence; Thomas Newman (trans.)
1627
Antigone the Theban Princess
ATP
Thomas May
1627
Salting: A Meal (Thomas Randolph’s Salting)
TRSM
Thomas Randolph
1627
The Pedlar (The Conceited Pedlar)
Ped
Thomas Randolph
1627
Hey for Honesty, Down with Knavery
HeyH
Thomas Randolph
1627
Amynta
Amya
Torquato Tasso; Henry Reynolds (trans.)
1627
The Cruel Brother
CBro
William Davenport
1627
Apollo Shroving
ApSh
William Hawkins
1627
The Witty Fair One
WFO
James Shirley
1628
The Lover’s Melancholy
LMel
John Ford
1628
Pastoral Entertainment (Shepherds and Shepherdesses)
PasE
Rachel Fane
1628
Temperance and Mirth (Lady Temperance)
TemM
Rachel Fane
1628
King John and Matilda (John and Matilda)
KJM
Robert Davenport
1628
Lodovic Sforza, Duke of Milan
Sfor
Robert Gomersall
1628
Britannia’s Honour
BriH
Thomas Dekker
1628
Julia Agrippina, Empress of Rome
Agrp
Thomas May
1628
The Vow-Breaker (The Fair Maid of Clifton)
VowB
William Sampson
1628
The New Inn (The Light Heart)
NInn
Ben Jonson
1629
A Contention for Honour and Riches
CHR
James Shirley
1629
The Faithful Servant (The Grateful Servant)
FSer
James Shirley
1629
The Broken Heart
BHea
John Ford
1629
The Deserving Favourite
DesF
Lodowick Carlell
1629
The Picture
Pict
Philip Massinger
1629
The Northern Lass
NorL
Richard Brome
1629
Andria (The Woman of Andros)
Andr
Terence; Joseph Webbe (trans.)
1629
Eunuchus (The Eunuch)
Euns
Terence; Joseph Webbe (trans.)
1629
London’s Tempe (The Field of Happiness)
LonT
Thomas Dekker
1629
A Maidenhead Well Lost
MWL
Thomas Heywood
1629
The Drinking Academy (The Cheaters’ Holiday)
DrAc
Thomas Randolph
1629
The Just Italian
JIta
William Davenant
1629
The Jews’ Tragedy
JewT
William Heminges
1629
Alphonsus, Emperor of Germany
AEG
Anonymous
1630
The Anti-Bishop (Hierarchomachia)
AntB
Anonymous
1630
The Inconstant Lady
IncL
Arthur Wilson
1630
Il pastor fido (The Faithful Shepherd)
SIPF
Giambattista Guarini; Jonathan Sidnam (trans.)
1630
The Soldered Citizen (The Soddered Citizen)
SCit
John Clavell
1630
The Twice-Changed Friar
TCF
John Newdigate
1630
Masque at Whitton
MWht
John Suckling
1630
Icaromenippus
Icar
Lucian; Francis Hickes (trans.)
1630
Menippus
Meni
Lucian; Francis Hickes (trans.)
1630
The Dream (The Cock)
Drm
Lucian; Francis Hickes (trans.)
1630
The Infernal Ferry (The Tyrant)
InfF
Lucian; Francis Hickes (trans.)
1630
Charon (The Surveyors)
Chrn
Lucian; Francis Hickes (trans.)
1630
Timon (The Man-Hater)
Tmn
Lucian; Francis Hickes (trans.)
1630
Lucian’s Feast (The Lapiths)
LucF
Lucian; Francis Hickes (trans.)
1630
The Maid of Honour
MaiH
Philip Massinger
1630
The Wishing Chair (Country House Masque of Seasons and Shepherdesses)
WChr
Rachel Fane
1630
2 The Fair Maid of the West (The Fair Maid of the West, Part Two)
2FMW
Thomas Heywood
1630
The Old Couple
OldC
Thomas May
1630
The Muses’ Looking-Glass
MLG
Thomas Randolph
1630
Amyntas (The Impossible Dowry)
Amnt
Thomas Randolph
1630
The Switzer (The Swisser)
Swr
Arthur Wilson
1631
Love’s Triumph Through Callipolis
Calli
Ben Jonson
1631
Chloridia
Chlo
Ben Jonson
1631
Filli di Sciro (Phyllis of Scyros)
PhSc
Guidobaldo della Rovere Bonarelli; Jonathan Sidnam (trans.)
1631
The Traitor
Trai
James Shirley
1631
The Humorous Courtier (The Duke)
HumC
James Shirley
1631
Love’s Cruelty
LCru
James Shirley
1631
’Tis Pity She’s a Whore
Pity
John Ford
1631
The Emperor of the East
EmpE
Philip Massinger
1631
Believe as You List
BYL
Philip Massinger
1631
Rhodon and Iris
Rho
Ralph Knevet
1631
Holland’s Leaguer
HLgr
Shackerley Marmion
1631
Janus
Jan
Thomas Heywood
1631
London’s Jus Honorarium
LJH
Thomas Heywood
1631
The Corporal
Corp
Arthur Wilson
1632
The Obstinate Lady
ObL
Aston Cokayne
1632
Albion’s Triumph
AlbT
Aurelian Townshed
1632
Tempe Restored
TemR
Aurelian Townshed
1632
The Magnetic Lady
MagL
Ben Jonson
1632
The Changes (Love in a Maze)
Chgs
James Shirley
1632
Hyde Park
HydP
James Shirley
1632
The Ball
Ball
James Shirley
1632
Masque of Soldiers
MSol
John Clavell
1632
Love’s Sacrifice
LSac
John Ford
1632
The Emperor’s Favourite (Nero)
EmpF
John Newdigate
1632
Love Crowns the End
LCE
John Tatham
1632
The Rival Friends
RivF
Peter Hausted
1632
The City Madam
CitM
Philip Massinger
1632
The Novella
Nov
Richard Brome
1632
A Fine Companion
FCom
Shackerley Marmion
1632
The Sad One
SadO
Sir John Suckling
1632
The Country Girl
CGrl
T. B.; Anonymous
1632
London’s Fountain of Arts and Sciences (Londini artium et scientiarum scaturigo)
LFA
Thomas Heywood
1632
Money is an Ass (Wealth Outwitted)
MAss
Thomas Jordan
1632
The Jealous Lovers
JLo
Thomas Randolph
1632
Necromantes (The Two Supposed Heads)
Necr
William Percy
1632
The New Moon
NMn
Anonymous
1633
Trappolin Supposed a Prince
Trap
Aston Cokayne
1633
A Tale of a Tub
TTub
Ben Jonson
1633
Royal Entertainment at Welbeck Abbey
Welb
Ben Jonson
1633
The Amazon
Amaz
Edward Herbert
1633
The Bird in a Cage (The Beauties)
Bird
James Shirley
1633
The Young Admiral
YAdm
James Shirley
1633
The Gamester
Gams
James Shirley
1633
Royal Entry of King Charles I into Edinburgh
C1Ed
John Adamson; Thomas Crawford?; William Drummond
1633
Perkin Warbeck
Perk
John Ford
1633
The Shepherds’ Holiday
ShHo
Joseph Rutter
1633
The Guardian
Guar
Philip Massinger
1633
The Weeding of Covent Garden
Weed
Richard Brome
1633
The City Wit
CWit
Richard Brome
1633
London’s Markets (Londini emporia)
LonM
Thomas Heywood
1633
Hospitality and Delight
HosD
Thomas Heywood
1633
The Cunning Lovers
CunL
Thomas Heywood; Richard Brome
1633
Tottenham Court
TotC
Thomas Nabbes
1633
The Rebellion
Reb
Thomas Rawlins
1633
The Shepherds’ Paradise
ShPa
Walter Montagu
1633
The Launching of the Mary (The Seaman’s Honest Wife)
LMa
Walter Mountfort
1633
The Fatal Contract (The Eunuch)
FCon
William Heminges
1633
Love’s Riddle
LRid
Abraham Cowley
1634
Love’s Welcome at Bolsover
EBol
Ben Jonson
1634
The Triumph of Peace
TrPc
James Shirley
1634
The Triumph of Beauty
TrBy
James Shirley
1634
The Example
Ex
James Shirley
1634
The Opportunity
Opp
James Shirley
1634
The Seven Champions of Christendom
SCC
John Kirke
1634
Arcades (The Arcadians)
Arcd
John Milton
1634
Comus (A Masque at Ludlow Castle)
Cmus
John Milton
1634
The Humorous Magistrate
HMag
John Newdigate
1634
The Triumphs of Fame and Honour
TrFH
John Taylor
1634
The Queen’s Exchange (The Royal Exchange)
QEx
Richard Brome
1634
A Dialogue between Policy and Piety
DPoP
Robert Davenport
1634
Coelum Britannicum (The British Heaven)
CoeB
Thomas Carew
1634
A Challenge for Beauty
CFB
Thomas Heywood
1634
Love’s Mistress (The Queen’s Masque) (Cupid and Psyche)
LMis
Thomas Heywood
1634
The Witches of Lancashire (The Late Lancashire Witches)
WLan
Thomas Heywood; Richard Brome
1634
Covent Garden
CovG
Thomas Nabbes
1634
Entertainment at Chirk Castle
Chrk
Thomas Salisbury?
1634
The Christmas Antimasque
CCM
William Cavendish
1634
The Wits
Wits
William Davenant
1634
Love and Honour (The Courage of Love)
LaH
William Davenant
1634
The Duke of Florence (Tragedy of Prince Alexander and Lorenzo)
DFlo
Anonymous
1635
Love’s Changelings’ Change
LoCC
Anonymous
1635
The Partial Law
PrtL
Anonymous
1635
Pastoral Court Masque (The Antimasques)
Anti
Aurelian Townshed
1635
Naiagaion (The Shipwreck)
HNai
Desiderius Erasmus; Thomas Heywood (trans.)
1635
Procus et puella (The Suitor and the Girl)
HPro
Desiderius Erasmus; Thomas Heywood (trans.)
1635
Freewill (Free Will)
FrWi
Francis Bristowe (trans.); Francesco Negri de Bassano
1635
The Christmas Ordinary
ChOr
Henry Birkhead?
1635
The Lady Mother
LaMo
Henry Glapthorne
1635
The Conspiracy (Pallantus and Eudora)
Cspy
Henry Killigrew
1635
The Strange Discovery
SDis
J. Gough; Anonymous
1635
The Coronation
Coro
James Shirley
1635
The Arcadia
Arca
James Shirley
1635
The Lady of Pleasure
LaPl
James Shirley
1635
Adrasta (The Woman’s Spleen and Love’s Conquest)
Adra
John Jones
1635
The Converted Robber (Stonehenge)
ConR
John Speed
1635
Misanthropos (The Man-Hater)
HMis
Lucian; Thomas Heywood (trans.)
1635
Jupiter and Ganymede
HJGa
Lucian; Thomas Heywood (trans.)
1635
Jupiter and Juno
HJJu
Lucian; Thomas Heywood (trans.)
1635
Jupiter and Cupid
HJCu
Lucian; Thomas Heywood (trans.)
1635
Vulcan and Apollo
HVAp
Lucian; Thomas Heywood (trans.)
1635
Mercury and Apollo
HMAp
Lucian; Thomas Heywood (trans.)
1635
Mercury and Maia
HMMa
Lucian; Thomas Heywood (trans.)
1635
Vulcan and Jupiter
HVJu
Lucian; Thomas Heywood (trans.)
1635
Neptune and Mercury
HNMe
Lucian; Thomas Heywood (trans.)
1635
Diogenes and Mausolus
HDMa
Lucian; Thomas Heywood (trans.)
1635
Crates and Diogenes
HCDi
Lucian; Thomas Heywood (trans.)
1635
Charon, Menippus, Mercury
HCMM
Lucian; Thomas Heywood (trans.)
1635
The Nirusrsites, Menippus
HNTM
Lucian; Thomas Heywood (trans.)
1635
Deorum iudicium (The Judgement of the Gods)
HJGo
Lucian; Thomas Heywood (trans.)
1635
Messalina, the Roman Empress
Mess
Nathaniel Richards
1635
The Dialogue betwixt Earth and Age
HDEA
Ravisius Textor; Thomas Heywood (trans.)
1635
The Sparagus Garden
Spar
Richard Brome
1635
The Queen and Concubine
QCon
Richard Brome
1635
The Antiquary
Antq
Shackerley Marmion
1635
Jupiter and Io
HJIo
Thomas Heywood
1635
Apollo and Daphne
HADa
Thomas Heywood
1635
Amphrisa (The Foresaken Shepherdess)
HAmp
Thomas Heywood
1635
London’s Harbour of Health (Londini sinus salutis)
LnHH
Thomas Heywood
1635
The Prisoners
Prsn
Thomas Killigrew
1635
Hannibal and Scipio
Hann
Thomas Nabbes
1635
The Ordinary (The City Cozener)
Ord
William Cartwright
1635
Wit’s Triumvirate (The Philosopher)
WTrv
William Cavendish
1635
Templum amoris (The Temple of Love)
TemL
William Davenant
1635
News of Plymouth (News from Plymouth)
NewP
William Davenant
1635
The Platonic Lovers
Plat
William Davenant
1635
Floral Play (Norwich)
NFlo
William Strode
1635
The Wasp
Wasp
Anonymous
1636
A Fiddler and a Poet
FidP
Anonymous
1636
The Faithless Relict (The Cyprian Conqueror)
CypC
Anonymous
1636
Royal Entertainment at Richmond Palace
RERm
Anonymous
1636
Masque of Mariners
MMar
Aurelian Townshed
1636
Corona Minervae (The Crown of Minerva)
CorM
Francis Kynaston?
1636
The Hospital of Lovers (Love’s Hospital)
HosL
George Wilde
1636
The Hollander (Love’s Trial)
Holl
Henry Glapthorne
1636
Entertainment for the Elector Palatine
EEPa
Henry Glapthorne
1636
The Duke’s Mistress
DukM
James Shirley
1636
The City Match
CMat
Jasper Mayne
1636
The Fancies (The Fancies, Chaste and Noble)
FCN
John Ford
1636
1 Arviragus and Philicia (Arviragus and Philicia, Part One)
1Arv
Lodowick Carlell
1636
2 Arviragus and Philicia (Arviragus and Philicia, Part Two)
2Arv
Lodowick Carlell
1636
The Bashful Lover
BLov
Philip Massinger
1636
The New Academy (The New Exchange)
NewA
Richard Brome
1636
Dialogue betwixt a Citizen and a Poor Countryman and His Wife
DCPC
Thomas Brewer?
1636
Royal Entertainment at Enstone (The Presentment of Bushell’s Rock)
Enst
Thomas Bushell?; Thomas Jordan
1636
Play of a Jealous Lover
PJLo
Thomas Carew
1636
Masque of Ladies (The Masque at Hunsdon)
MHun
Thomas Heywood
1636
Claracilla
Clar
Thomas Killigrew
1636
The Princess (Love at First Sight)
PLFS
Thomas Killigrew
1636
Masque of Moors
MMrs
Thomas Moore
1636
Microcosmus
Mmus
Thomas Nabbes
1636
The Royal Slave
RSla
William Cartwright
1636
The Cutpurse (A Scene of a Cutpurse)
Cutp
William Cavendish
1636
The Triumphs of the Prince D’Amour
TPLo
William Davenant
1636
Love in Its Ecstasy (The Large Prerogative)
LEcs
William Peaps
1636
Passions Calmed (The Floating Island)
PasC
William Strode
1636
Mortimer’s Fall (Mortimer His Fall)
MHF
Ben Jonson
1637
The Sad Shepherd (A Tale of Robin Hood)
SadS
Ben Jonson
1637
Grobiana’s Nuptials
Grob
Charles May
1637
The Ladies’ Privilege (The Lady’s Privilege)
LPrv
Henry Glapthorne
1637
The Royal Master
RoyM
James Shirley
1637
Aglaura
Agla
John Suckling
1637
The Discreet Lover (The Fool Would Be a Favourite)
DisL
Lodowick Carlell
1637
The English Moor (The Mock Marriage)
EngM
Richard Brome
1637
London’s Mirror (Londini speculum)
LonS
Thomas Heywood
1637
The Ward
Ward
Thomas Neale
1637
The Lost Lady
LstL
William Berkeley
1637
The Lady Errant
LErr
William Cartwright
1637
The Pattern of Piety
PatP
Gyles Oldisworth
1638
Wit in a Constable
WCon
Henry Glapthorne
1638
Argalus and Parthenia
ArgP
Henry Glapthorne
1638
The Constant Maid (Love Will Find Out the Way)
ConM
James Shirley
1638
The Doubtful Heir (Rosania, or Love’s Victory)
DbtH
James Shirley
1638
The Amorous War
AWar
Jasper Mayne
1638
The Lady’s Trial
LadT
John Ford
1638
The Goblins
Gob
John Suckling
1638
1 The Passionate Lovers (The Passionate Lovers, Part One)
1PL
Lodowick Carlell
1638
2 The Passionate Lovers (The Passionate Lovers, Part Two)
2PL
Lodowick Carlell
1638
1 The Cid (The Valiant Cid) (The Cid, Part One)
1Cid
Pierre Corneille; Joseph Rutter (trans.)
1638
2 The Cid (The Cid, Part Two)
2Cid
Pierre Corneille; Joseph Rutter (trans.)
1638
The Antipodes
Apds
Richard Brome
1638
The Damoiselle (The New Ordinary)
Damo
Richard Brome
1638
The Combat of Love and Friendship
CoLF
Robert Mead
1638
The Wizard
Wiz
Simon Baylie
1638
Porta Pietatis (The Port of Piety)
PoPi
Thomas Heywood
1638
Spring’s Glory
SGlo
Thomas Nabbes
1638
Time and the Almanac-Makers
TAM
Thomas Nabbes
1638
The Bride
Brid
Thomas Nabbes
1638
The Siege (Love’s Convert)
Sieg
William Cartwright
1638
The Unfortunate Lovers
UnfL
William Davenant
1638
Britannia Triumphans (Britain Triumphing)
BriT
William Davenant
1638
Luminalia (The Festival of Light)
Lum
William Davenant
1638
Albertus Wallenstein
AlbW
Henry Glapthorne
1639
1 Saint Patrick for Ireland (Saint Patrick for Ireland, Part One)
1SPI
James Shirley
1639
The Gentleman of Venice
GVen
James Shirley
1639
The Politician
Poln
James Shirley
1639
Brennoralt (The Discontented Colonel)
Bren
John Suckling
1639
The Noble Stranger
NStr
Lewis Sharpe
1639
Imperiale
Impe
Ralph Freeman
1639
A Mad Couple Well Matched
MadC
Richard Brome
1639
The Lovesick Court
LovC
Richard Brome
1639
London’s Peaceable Estate (Londini status pacatus)
LnPE
Thomas Heywood
1639
The Unfortunate Mother
UnfM
Thomas Nabbes
1639
The Phoenix in Her Flames
PFla
William Lower
1639
The Ghost (The Woman Wears the Breeches)
WoWB
Anonymous
1640
A Masque at Bretbie
MBrt
Aston Cokayne
1640
Landgartha
Land
Henry Burnell
1640
Revenge for Honour (The Parricide)
RHon
Henry Glapthorne
1640
Christ’s Passion
SChP
Hugo Grotius; George Sandys (trans.)
1640
The Imposture (The Impostor)
Impr
James Shirley
1640
Masquerade du Ciel (A Celestial Masque)
MdC
John Sadler
1640
Raguaillo D’Oceano
RagD
Mildmay Fane
1640
The Court Beggar
CBeg
Richard Brome
1640
The Swaggering Damsel
Swag
Robert Chamberlaine
1640
Sicily and Naples (The Fatal Union)
SicN
Samuel Harding
1640
The Country Captain (Captain Underwit)
CCap
William Cavendish; James Shirley
1640
Salmacida Spoila
Salm
William Davenant
1640
The Queen of Aragon (Cleodora)
QAr
William Habington
1640
The Twins
Twns
William Rider
1640
Canterbury’s Change of Diet (Canterbury His Change of Diet)
CHCD
Anonymous
1641
The Virgin Widow
VWid
Francis Quarles
1641
The Brothers (The Politic Father)
Bros
James Shirley
1641
The Cardinal
Card
James Shirley
1641
The Sophy
Sphy
John Denham
1641
Candy Restored (Candia Restaurata)
CanR
Mildmay Fane
1641
Mercurius Britannicus (The English Intelligencer)
MerB
Richard Braithwait
1641
A Jovial Crew (The Merry Beggars)
JCrw
Richard Brome
1641
The Walks of Islington and Hoxton (Tricks of Youth)
WIH
Thomas Jordan
1641
A Masque at Knowsley
MKnw
Thomas Salisbury
1641
The Variety
Vari
William Cavendish
1641
The Guardian (The Cutter of Coleman Street)
GCCS
Abraham Cowley
1642
Andromana (The Merchant’s Wife)
Anda
J. S.; Anonymous
1642
The Sisters
Sist
James Shirley
1642
The Court Secret
CSec
James Shirley
1642
The Change
FChn
Mildmay Fane
1642
Time’s Trick upon the Cards
TTUC
Mildmay Fane
1642
The Queen of Corsica
QCrs
Francis Jaques
1642
A Discourse Concerning Evil Counsellers
DCEC
Anonymous
1643
Time’s Triumph (Sight and Search, Juno in Arcadia)
TimT
Anonymous; Mildmay Fane?
1643
Virtue’s Triumph
VirT
Mildmay Fane
1644
The Concealed Fancies
ConF
Elizabeth Brackley; Jane Cavendish
1645
A Pastoral
CBP
Elizabeth Brackley; Jane Cavendish
1645
Cola’s Fury (Lirenda’s Misery)
CFur
Henry Burkhead
1645
Don Phoebo’s Triumph
DPTr
Mildmay Fane
1645
News Out of the West (The Character of a Mountebank)
NOWe
Anonymous
1647
The Scottish Politic Presbyter Slain
SPPS
Anonymous
1647
Il pastor fido (The Faithful Shepherd)
FIPF
Giambattista Guarini; Richard Fanshawe (trans.)
1647
The Levellers Levelled
LevL
Marchmont Nedham
1647
Gripsius and Hegio (The Passionate Lovers)
Grip
Robert Baron
1647
Deorum Dona
DeDo
Robert Baron
1647
1 The Committee-Man Curried (The Committee-Man Curried, Part One)
1CMC
Samuel Sheppard
1647
2 Committee-Man Curried (The Committee-Man Curried, Part Two)
2CMC
Samuel Sheppard
1647
1 Crafty Cromwell (Oliver Ordering Our New State, Part One)
1CC
Anonymous
1648
2 Crafty Cromwell (Oliver Ordering Our New State, Part Two)
2CC
Anonymous
1648
The Devil and the Parliament
DevP
Anonymous
1648
Ding-Dong (Sir Pitiful Parliament on His Deathbed)
DDng
Anonymous
1648
The Kentish Fair (Parliament Sold to Their Best Worth)
KenF
Anonymous
1648
Mistress Parliament Brought to Bed
MPBB
Anonymous
1648
Mistress Parliament Presented in Her Bed
MPPB
Anonymous
1648
Mistress Parliament’s Gossipping (Mistress Parliament, Her Gossiping)
MPHG
Anonymous
1648
Mistriss Parliament’s Invitation of Mistress London
MPIL
Anonymous
1648
Medea
SMed
Seneca; Edward Sherburne (trans.)
1648
A Bartholomew Fairing
BFai
Anonymous
1649
The Charles the First Famous Tragedy of
C1
Anonymous
1649
The Disease of the House (The State Mountebank Administering to a Sick Parliament)
DisH
Anonymous
1649
Electra
WEle
Anonymous; Wase (trans.)
1649
A New Bull-Baiting
NBB
Anonymous
1649
1 Newmarket Fair (Newmarket Fair, Part One)
1NF
Anonymous
1649
2 Newmarket Fair (Newmarket Fair, Part Two)
2NF
Anonymous
1649
Women Will Have Their Will (Give Christmas His Due)
WoWW
Anonymous
1649
The Rebellion of Naples (The Tragedy of Massenello)
RNap
T. B.; Anonymous
1649
The White Ethiopian
WEth
Anonymous
1650
The Dutch Lady
DutL
Anonymous
1650
The Distracted State
DisS
John Tatham
1650
De Pugna Animi
DPAn
Mildmay Fane
1650
Marcus Tullius Cicero
MTC
Anonymous
1651
The Prince of Prigs’ Revels
Prig
J. S.; Anonymous
1651
Astraea (Love’s True Mirror)
ALTM
Leonard Willan
1651
The Devil Turned Ranter (The Jovial Crew)
DTR
Samuel Sheppard
1651
Hyppolytus
PHyp
Seneca; Edmund Prestwich (trans.)
1651
The Bastard
Bast
Anonymous
1652
The Just General
JusG
Cosmo Manuche
1652
The Loyal Lovers
LoyL
Cosmo Manuche
1652
Sophompaneas (Joseph)
Sphm
Hugo Grotius; Francis Goldsmith (trans.)
1652
The Scots Figaries (A Knot of Knaves)
SFig
John Tatham
1652
Cupid and Death
CupD
James Shirley
1653
Actaeon and Diana
ActD
Robert Cox
1653
Rural Sports (The Birth of the Nymph Oenone)
RurS
Robert Cox
1653
John Swabber
JnSw
Robert Cox
1653
Simpleton the Smith
SimS
Robert Cox
1653
The True Tragicomedy of Robert Carr and Francis Howard
RCFH
Anonymous
1654
1 The Nuptials of Peleus and Thetis (The Great Royal Ball) (The Nuptials of Peleus and Thetis, Part One)
1NPT
James Howell (trans.)
1654
2 Nuptials of Peleus and Thetis (The Great Royal Ball) (The Nuptials of Peleus and Thetis, Part Two)
2NPT
James Howell (trans.)
1654
Ariadne (Ariadne Deserted by Theseus)
ADT
Richard Flecknoe
1654
Love’s Dominion
LovD
Richard Flecknoe
1654
The Extravagant Shepherd
ExSh
T. R. (trans.); Anonymous (trans.); Thomas Corneille
1654
Cupid’s Coronation
CupC
Thomas Jordan
1654
The Gossips’ Brawl (The Women Wear the Breeches)
GosB
Anonymous
1655
The Clouds
Clds
Aristophanes; Thomas Stanley (trans.)
1655
Polyeuctes (The Martyr)
Poly
Pierre Corneille; William Lower (trans.)
1655
Mirza
Mrza
Robert Baron
1655
The Hectors (The False Challenge)
Hecs
Anonymous
1656
London’s Triumph for Robert Tichborne
LTRT
J. B.; Anonymous
1656
Horatius
Hora
Pierre Corneille; William Lower (trans.)
1656
Venus and Adonis
VenA
Samuel Holland
1656
1 The Siege of Rhodes (The Siege of Rhodes, Part One)
1SR
William Davenant
1656
The First Day’s Entertainment at Rutland House
FDRH
William Davenant
1656
The False Favourite Disgraced (The Reward of Loyalty)
FFD
George Gerbier D’Ouvilley
1657
London’s Triumphs for Richard Chiverton
LTRC
John Tatham
1657
Fancy’s Festivals
FanF
Thomas Jordan
1657
The Unhappy Fair Irene
UFI
Gilbert Swinhoe
1658
Honoria and Mammon
HMam
James Shirley
1658
The Contention of Ajax and Ulysses
CnAU
James Shirley
1658
London’s Triumph for John Ireton (Industry and Honour)
LTJI
John Tatham
1658
Orgula (The Fatal Error)
Orgu
Leonard Willan
1658
Love and War
LWar
Thomas Meriton
1658
The Wandering Lover
WanL
Thomas Meriton
1658
Love’s Victory
CLVc
William Chamberlaine
1658
The Cruelty of the Spaniards in Peru
Peru
William Davenant
1658
1 Sir Francis Drake (Sir Francis Drake, Part One)
1SFD
William Davenant
1658
The Enchanted Lovers
EntL
William Lower
1658
The London Chanticleers
LCha
Anonymous
1659
Lady Alimony (The Alimony Lady)
LAli
Anonymous
1659
Alfred (Right Re-Enthroned)
ARRE
Anonymous
1659
Plutus (The World’s Idol)
Plut
Aristophanes; H. H. B. (trans.); Anonymous (trans.)
1659
London’s Triumph for Thomas Allen
LTTA
John Tatham
1659
The Belly Wager (Self-Interest)
SIBW
Nicolo Secchi; William Reymes (trans.)
1659
The Noble Ingratitude
NIng
Philippe Quinault; William Lower (trans.)
1659
The Amorous Fantasm
AmFa
Philippe Quinault; William Lower (trans.)
1659
The Marriage of Oceanus and Britannia
MOBr
Richard Flecknoe
1659
Cromwell’s Conspiracy
CrmC
Anonymous
1660
The Banished Shepherdess
BShp
Cosmo Manuche
1660
The Escapes of Jupiter
EJup
Thomas Heywood
1627
Comedy of Timon
CTim
Anonymous
1602
The Captive Lady
CLad
Anonymous
1618-1625
Heteroclitanomalonomia
Het
Anonymous
1613
Comical Show about a Barber-Surgeon (Preist the Barber, Sweetball his Man)
PRSM
Anonymous
1611
Induction to The Hungry Courtier
InHC
Thomas Randolph
1630
The Parson’s Wedding
ParW
Thomas Killigrew
1641
Royal Entertainment at Cowdray
RECw
Anonymous
1591
Royal Entertainment at Elvetham
REEl
Nicholas Breton
1591
Royal Entertainment at Mitcham
REMh
Anonymous
1598
Royal Entertainment at Bisham Abbey
REBA
Anonymous
1592
Royal Entertainment at Chiswick
RECh
John Lyly
1602
The Convent of Pleasure
CnPl
Margaret Cavendish
1665
Renditions Taxonomy
LEMDO’s rendition taxonomy allows us to easily capture the composition and mise-en-page
of early modern books when we encode semi-diplomatic transcriptions.
Only use these values in semi-diplomatic transcriptions (i.e., in files with ldtPrimaryTextandletSemiDiplomatic in their
<catRef>
elements).
Rendition Values
The following table shows the renditions that LEMDO has created for use in semi-diplomatic
transcriptions. Encoders can use them to capture key features of their copytext without
needing knowledge of Cascading Style Sheets (CSS).
Brett Greatley-Hirsch is Professor of Renaissance Literature and Textual Studies at
the University of Leeds. He is a coordinating editor of Digital Renaissance Editions, co-editor of the Routledge journal Shakespeare, and a Trustee of the British Shakespeare Association. He is the author (with Hugh
Craig) of Style, Computers, and Early Modern Drama: Beyond Authorship (Cambridge, 2017), which brings together his interests in early modern drama, computational
stylistics, and literary history. His current projects include editions of Hyde Park for the Oxford Shirley (with Mark Houlahan) and Fair Em for DRE, a history of the editing and publishing of Renaissance drama from the eighteenth
century to the present day, and several computational studies of early modern dramatic
authorship and genre. For more details, see notwithoutmustard.net.
Illya
Illya has a BA in English and Sociocultural Anthropology and an MA in English. Prior
to joining the HCMC, he was a PhD candidate in English and Book History at the University
of Toronto and worked on Records of Early English Drama and on the Modernist Archives Publishing Project. His work at the HCMC focuses on creating web-based applications for research projects
led by members of the faculty of Humanities at the University of Victoria. This involves
creating schemas for new and existing datasets, writing XSLT and build files to transform
datasets into structured TEI and HTML formats, implementing staticSearch, and ensuring
that new projects are Endings Principles compliant.
Janelle Jenstad
Janelle Jenstad is a Professor of English at the University of Victoria, Director
of The Map of Early Modern London, and Director of Linked Early Modern Drama Online. With Jennifer Roberts-Smith and Mark Beatrice Kaethler, she co-edited Shakespeare’s Language in Digital Media: Old Words, New Tools (Routledge). She has edited John Stow’s A Survey of London (1598 text) for MoEML and is currently editing The Merchant of Venice (with Stephen Wittek) and Heywood’s 2 If You Know Not Me You Know Nobody for DRE. Her articles have appeared in Digital Humanities Quarterly, Elizabethan Theatre, Early Modern Literary Studies, Shakespeare Bulletin, Renaissance and Reformation, and The Journal of Medieval and Early Modern Studies. She contributed chapters to Approaches to Teaching Othello (MLA); Teaching Early Modern Literature from the Archives (MLA); Institutional Culture in Early Modern England (Brill); Shakespeare, Language, and the Stage (Arden); Performing Maternity in Early Modern England (Ashgate); New Directions in the Geohumanities (Routledge); Early Modern Studies and the Digital Turn (Iter); Placing Names: Enriching and Integrating Gazetteers (Indiana); Making Things and Drawing Boundaries (Minnesota); Rethinking Shakespeare Source Study: Audiences, Authors, and Digital Technologies (Routledge); and Civic Performance: Pageantry and Entertainments in Early Modern London (Routledge). For more details, see janellejenstad.com.
Joey Takeda
Joey Takeda is LEMDO’s Consulting Programmer and Designer, a role he assumed in 2020
after three years as the Lead Developer on LEMDO.
Kate LeBere
Project Manager, 2020–2021. Assistant Project Manager, 2019–2020. Textual Remediator
and Encoder, 2019–2021. Kate LeBere completed her BA (Hons.) in History and English
at the University of Victoria in 2020. During her degree she published papers in The Corvette (2018), The Albatross (2019), and PLVS VLTRA (2020) and presented at the English Undergraduate Conference (2019), Qualicum History
Conference (2020), and the Digital Humanities Summer Institute’s Project Management
in the Humanities Conference (2021). While her primary research focus was sixteenth
and seventeenth century England, she completed her honours thesis on Soviet ballet
during the Russian Cultural Revolution. She is currently a student at the University
of British Columbia’s iSchool, working on her masters in library and information science.
Mahayla Galliford
Project Manager, 2025-present; Assistant Project Manager, 2024-2025; Research Assistant,
2021-present. Mahayla Galliford (she/her) graduated from the University of Victoria
with a BA (honours with distinction) in 2024, and an MA English in 2026. Mahayla’s
undergraduate research explored early modern stage directions and civic water pageantry.
Her SSHRC-funded MA thesis project focuses on transcribing, editing, and encoding
early modern girls’ manuscripts, specifically Lady Rachel Fane’s May Masque in collaboration with LEMDO.
Martin Holmes
Martin Holmes has worked as a developer in the UVic’s Humanities Computing and Media
Centre for over two decades, and has been involved with dozens of Digital Humanities
projects. He has served on the TEI Technical Council and as Managing Editor of the
Journal of the TEI. He took over from Joey Takeda as lead developer on LEMDO in 2020.
He is a collaborator on the SSHRC Partnership Grant led by Janelle Jenstad.
Navarra Houldin
Training and Documentation Lead 2025–present. LEMDO project manager 2022–2025. Textual
remediator 2021–present. Navarra Houldin (they/them) completed their BA with a major
in history and minor in Spanish at the University of Victoria in 2022. Their primary
research was on gender and sexuality in early modern Europe and Latin America. They
are continuing their education through an MA program in Gender and Social Justice
Studies at the University of Alberta where they will specialize in Digital Humanities.
Samuel Seaberg
Samuel Seaberg, a University of Victoria English undergrad, enjoys riding his bike.
During the summer of 2025, he began working with LEMDO as a recipient of the Valerie
Kuehne Undergraduate Research Award (VKURA). Unfortunately, due to his summer being
spent primarily in working to establish an edition of Thomas Heywood’s If You Know Not Me, You Know Nobody, Part 2 and consequently working out how to represent multi-text works in a digital space,
his bike has suffered severely of sheltered seclusion from the sun. Note: Samuel now
works for LEMDO as the Assistant Project Manager, much to his bike’s chagrin.
Scott Matthews
Thomas Heywood
Tracey El Hajj
Junior Programmer 2019–2020. Research Associate 2020–2021. Tracey received her PhD
from the Department of English at the University of Victoria in the field of Science
and Technology Studies. Her research focuses on the algorhythmics of networked communications. She was a 2019–2020 President’s Fellow in Research-Enriched
Teaching at UVic, where she taught an advanced course on Artificial Intelligence and Everyday Life. Tracey was also a member of the Map of Early Modern London team, between 2018 and 2021. Between 2020 and 2021, she was a fellow in residence
at the Praxis Studio for Comparative Media Studies, where she investigated the relationships
between artificial intelligence, creativity, health, and justice. As of July 2021,
Tracey has moved into the alt-ac world for a term position, while also teaching in
the English Department at the University of Victoria.
Orgography
LEMDO Team (LEMD1)
The LEMDO Team is based at the University of Victoria and normally comprises the project
director, the lead developer, project manager, junior developers(s), remediators,
encoders, and remediating editors.
Queen’s Men Editions (QME1)
The Queen’s Men Editions anthology is led by Helen Ostovich, General Editor; Peter
Cockett, General Editor (Performance); Andrew Griffin, General Editor (Text; until
2026); and Janelle Jenstad, General Editor (Text; 2026–)