Alternate (alt) text is text that describes the content of an image. Alt text is helpful
if a user cannot see an image (e.g., the user uses a screen reader1 or the image does not load).
Alt text is different from the image caption that editors may choose to write in the
<figDesc>
element because alt text gives a literal description of what is in the image. An
image caption, on the other hand, may be used to provide an image’s metadata or to
discuss what is depicted in the image. Alt text tends to give a more detailed description
and does not supply information not visible in the image. For information on how to
encode image captions with the
<figDesc>
element and on how to encode alt text with the
<desc>
element, go to Practice: Encode Alt Text and Image Captions.
Rationale
LEMDO adds alt text to improve website accessibility. Including alt text gives people
who use screen readers access to content that would otherwise be inaccessible. This
documentation will guide you through LEMDO’s principles and practice for writing alt
text.
Principles
When writing alt text, LEMDO follows principles of accessibility, honesty, and clarity.
Consider the following questions when you write alt text:
Does my alt text communicate the key components of this image?
Is there anything significant that a viewer of this image would see that a reader
would not get out of my alt text?
Does my alt text truthfully describe what is in the image?
Does my alt text include subjective terms (e.g., describing someone as pretty or happy), or objective ones (e.g., descibing characteristics such as using a wheelchair or smiling)? Replace subjective terms with objective ones.
Is my alt text concise?
Practice: Write Alt Text
Follow these steps to write alt text for the LEMDO project:
Capture important elements of the image: Because alt text is meant to describe an
image to someone who cannot view it, alt text should capture aspects that are important
to the overall meaning of the image for the argument. For LEMDO, this typically includes
the medium (a photograph, a wood engraving, etc.), the main subject of the image,
important imagery, and background.
Include the race of all human main subjects: LEMDO has decided to include the race
of people who are the subject of images, as race will be a point of discussion in
many editions. In practice, capitalize the first letter of Indigenous and Black; do
not capitalize white. Use the most accurate term for a person’s race or ethnicity
that you can (e.g., if you know that an actor in an image is Piikani, describe them
as Piikani rather than the more generic Indigenous). When describing a living or historical
person rather than a character, search to see if there is information available about
how they identify or identified to use the most accurate and respectful language.
Use objective language: Alt text has the goal of describing what is literally in an
image, not the interpretation of a viewer or describer. To fulfill that goal, use
objective language (describing what you see) rather than subjective language (describing
how the image makes you feel or how you interpret it). For example, do say A photo of smiling children rather than A photo of happy children.
Use concise language: Although there are typically no restrictions in the number of
characters that modern screen readers will read, some programs do not continuously
read long strings of alt text. Even with new technology, best practice is to have
relatively short and concise descriptions. If possible, keep descriptions under 125
characters.
Do not use quotation marks: Quotation marks in alt text can cause processing issues.
If quoting text included in an image, write Text reads: or a similar descriptive phrase followed by a transcription of the text.
Transcribe relevant sections of text: If there is text in the image (e.g., a title
or an artist’s signature), transcribe any section that may be relevant or that will
be discussed. If there are glyphs or ligatures (e.g., a long S), normalize the characters.
If the image includes old-spelling text, modernize it in your transcription to make
the screen readers’ output more clear. In cases where you have modernized spelling,
note that in the preferatory clause (i.e., Modernized version of text reads:). Note that alt text for images containing text will typically be necessarily long.
Special case: If an image with text is included for the purpose of demonstrating or
discussing early modern spelling conventions, provide a semi-diplomatic transcription.
Normalize glyphs and ligatures without tagging them, but retain spelling as it appears
in the image. You may also provide a modernized transcription afterwards for clarity—not
all words will be read clearly by screen readers if spelled using early modern spelling
conventions.
Examples
This image:
Is described by this alt text:
<desc resp="pers:HOUL3">A wood engraving of Henry V gesturing to dismiss Falstaff in front of his entourage
near Westminster Abbey. Henry is a muscular white man on horseback. Falstaff is a
fat, short, and balding white man standing on the ground speaking up to Henry. Text
underneath reads: Drawn by C. Robinson; Engraved by T. Robinson. Description underneath
reads: King Henry V. and Falstaff. Falstaff. My king! my Jove! I speak to thee, my
heart! King. I know thee not, old man: fall to thy prayers. Henry IV., Part II., Act
V., Scene IV.</desc>
This image:
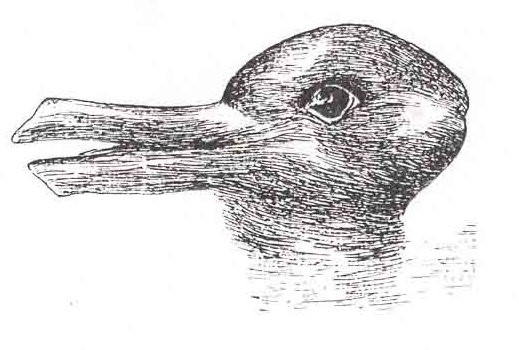
Is described by this alt text:
<desc resp="pers:HOUL3">A sketch of an animal that appears to be a duck from one angle and a rabbit from another.</desc>
This image:
Is described by this alt text:
<desc resp="pers:HOUL3">A book page with a sketch of a flour bolt sifting grains out of flour surrounded by
a decorative border. Modernized version of the text below reads: In fruitful field
amid the goodly crop, The hurtful tears, and darnel oft do grow, And many times, do
mount above the top Of highest corn: But skilfull man doth know, When grain is ripe,
with sieve to purge the seeds, From chaff, and dust, and all the other weeds. By which
is meant, sith wicked men abound, That hard it is, the good from bad to try: The prudent
sort, should have such judgement sound, That still the good they should from bad descry:
And sift the good, and to discern their deeds, And weigh the bad, no better than the
weeds.</desc>
This image:
Is described by this alt text:
<desc resp="pers:HOUL3">White text on a black background reads: C:\Users\jenstad\lemdo\data\texts\MV greater-than
angle bracket svn status / M main\emdMV_Q1.xml</desc>
This image:
Relationship of HCMC Server at UVic to Your Local Workstation Is described by this alt text:
<desc resp="pers:HOUL3">A graphic shows a cycle beginning at Subversion Repository (the repo) on HCMC Server
at UVic. An arrow labelled svn up points to Your local workstation. An arrow labelled
svn commit points from your workstation to the subversion repository.</desc>
1.A screen reader is a type of technology that audibly reads the content of a screen.
Screen readers are helpful to people with disabilities such as people who are blind
or have vision impairments.↑
Prosopography
Illya
Illya has a BA in English and Sociocultural Anthropology and an MA in English. Prior
to joining the HCMC, he was a PhD candidate in English and Book History at the University
of Toronto and worked on Records of Early English Drama and on the Modernist Archives Publishing Project. His work at the HCMC focuses on creating web-based applications for research projects
led by members of the faculty of Humanities at the University of Victoria. This involves
creating schemas for new and existing datasets, writing XSLT and build files to transform
datasets into structured TEI and HTML formats, implementing staticSearch, and ensuring
that new projects are Endings Principles compliant.
Janelle Jenstad
Janelle Jenstad is a Professor of English at the University of Victoria, Director
of The Map of Early Modern London, and Director of Linked Early Modern Drama Online. With Jennifer Roberts-Smith and Mark Beatrice Kaethler, she co-edited Shakespeare’s Language in Digital Media: Old Words, New Tools (Routledge). She has edited John Stow’s A Survey of London (1598 text) for MoEML and is currently editing The Merchant of Venice (with Stephen Wittek) and Heywood’s 2 If You Know Not Me You Know Nobody for DRE. Her articles have appeared in Digital Humanities Quarterly, Elizabethan Theatre, Early Modern Literary Studies, Shakespeare Bulletin, Renaissance and Reformation, and The Journal of Medieval and Early Modern Studies. She contributed chapters to Approaches to Teaching Othello (MLA); Teaching Early Modern Literature from the Archives (MLA); Institutional Culture in Early Modern England (Brill); Shakespeare, Language, and the Stage (Arden); Performing Maternity in Early Modern England (Ashgate); New Directions in the Geohumanities (Routledge); Early Modern Studies and the Digital Turn (Iter); Placing Names: Enriching and Integrating Gazetteers (Indiana); Making Things and Drawing Boundaries (Minnesota); Rethinking Shakespeare Source Study: Audiences, Authors, and Digital Technologies (Routledge); and Civic Performance: Pageantry and Entertainments in Early Modern London (Routledge). For more details, see janellejenstad.com.
Joey Takeda
Joey Takeda is LEMDO’s Consulting Programmer and Designer, a role he assumed in 2020
after three years as the Lead Developer on LEMDO.
Mahayla Galliford
Project Manager, 2025-present; Assistant Project Manager, 2024-2025; Research Assistant,
2021-present. Mahayla Galliford (she/her) graduated from the University of Victoria
with a BA (honours with distinction) in 2024, and an MA English in 2026. Mahayla’s
undergraduate research explored early modern stage directions and civic water pageantry.
Her SSHRC-funded MA thesis project focuses on transcribing, editing, and encoding
early modern girls’ manuscripts, specifically Lady Rachel Fane’s May Masque in collaboration with LEMDO.
Martin Holmes
Martin Holmes has worked as a developer in the UVic’s Humanities Computing and Media
Centre for over two decades, and has been involved with dozens of Digital Humanities
projects. He has served on the TEI Technical Council and as Managing Editor of the
Journal of the TEI. He took over from Joey Takeda as lead developer on LEMDO in 2020.
He is a collaborator on the SSHRC Partnership Grant led by Janelle Jenstad.
Navarra Houldin
Training and Documentation Lead 2025–present. LEMDO project manager 2022–2025. Textual
remediator 2021–present. Navarra Houldin (they/them) completed their BA with a major
in history and minor in Spanish at the University of Victoria in 2022. Their primary
research was on gender and sexuality in early modern Europe and Latin America. They
are continuing their education through an MA program in Gender and Social Justice
Studies at the University of Alberta where they will specialize in Digital Humanities.
Nicole Vatcher
Technical Documentation Writer, 2020–2022. Nicole Vatcher completed her BA (Hons.)
in English at the University of Victoria in 2021. Her primary research focus was women’s
writing in the modernist period.
Samuel Seaberg
Samuel Seaberg, a University of Victoria English undergrad, enjoys riding his bike.
During the summer of 2025, he began working with LEMDO as a recipient of the Valerie
Kuehne Undergraduate Research Award (VKURA). Unfortunately, due to his summer being
spent primarily in working to establish an edition of Thomas Heywood’s If You Know Not Me, You Know Nobody, Part 2 and consequently working out how to represent multi-text works in a digital space,
his bike has suffered severely of sheltered seclusion from the sun. Note: Samuel now
works for LEMDO as the Assistant Project Manager, much to his bike’s chagrin.
Tracey El Hajj
Junior Programmer 2019–2020. Research Associate 2020–2021. Tracey received her PhD
from the Department of English at the University of Victoria in the field of Science
and Technology Studies. Her research focuses on the algorhythmics of networked communications. She was a 2019–2020 President’s Fellow in Research-Enriched
Teaching at UVic, where she taught an advanced course on Artificial Intelligence and Everyday Life. Tracey was also a member of the Map of Early Modern London team, between 2018 and 2021. Between 2020 and 2021, she was a fellow in residence
at the Praxis Studio for Comparative Media Studies, where she investigated the relationships
between artificial intelligence, creativity, health, and justice. As of July 2021,
Tracey has moved into the alt-ac world for a term position, while also teaching in
the English Department at the University of Victoria.
Orgography
LEMDO Team (LEMD1)
The LEMDO Team is based at the University of Victoria and normally comprises the project
director, the lead developer, project manager, junior developers(s), remediators,
encoders, and remediating editors.
Metadata
Authority title
Write Alternate Text for Images
Type of text
Documentation
Publisher
University of Victoria on the Linked Early Modern Drama Online Platform
Released with Linked Early Modern Drama Online 1.0
Encoding description
Encoded in TEI P5 according to the LEMDO Customization and Encoding Guidelines
Document status
prgGenerated
Funder(s)
Social Sciences and Humanities Research Council of Canada
License/availability
This file is licensed under a CC BY-NC_ND 4.0 license, which means that it is freely downloadable without permission under the following
conditions: (1) credit must be given to the author and LEMDO in any subsequent use
of the files and/or data; (2) the content cannot be adapted or repurposed (except
in quotations for the purposes of academic review and citation); and (3) commercial
uses are not permitted without the knowledge and consent of the editor and LEMDO.
This license allows for pedagogical use of the documentation in the classroom.